a16z: AIの次なるフロンティア、ロボット、自己主導型サイエンス、脳-コンピューターインターフェースの三位一体のフライホイール

原文タイトル:Frontier Systems for the Physical World
原著者:Oliver Hsu、a16z Crypto Researcher
翻訳:深潮 TechFlow
深潮の紹介: この記事はa16zの研究者Oliver Hsuによるもので、これまでで最も包括的な「物理AI」投資マップです。彼の見解では、言語/コードがまだスケーリング中である中、次世代を本当に変革する能力を持つのは、汎用ロボット、自律科学(AIサイエンティスト)、脳-機械インタフェースなど、主要ラインに密接に連なる3つの領域です。著者はこれらをサポートする5つの基本的能力を分析し、これら3つの戦線間で相互にフィードバックする構造的なフライホイールが形成されると論じています。物理AI投資ロジックを理解したい人にとって、これは現在最も包括的なフレームワークです。
今日のAIの主導パラダイムは、言語とコードの組織に焦点を当てています。大規模言語モデルのスケーリング法則は既に非常に明確に描かれており、データ、計算リソース、アルゴリズムの改善によるビジネスフライホイールが回転し、各段階での能力向上によるリターンは依然として非常に大きく、そしてそれらのリターンの大部分は目に見えます。このパラダイムは、それが吸収した資本と注意を値すると言えます。
しかしながら、別の一群の隣接領域は、既に成長段階に入り、具体的な進展を遂げています。ここには、VLA(Vision-Language-Actionモデル)、WAM(World Action Model)を含む汎用ロボットの経路、物理学と科学的推論に焦点を当てる「AI科学者」、AIを活用して人間とのインタラクションを再構築する新しいタイプのインタフェース(脳-機械インタフェースや神経科学技術を含む)が含まれます。
技術そのものだけでなく、これらの方向それぞれが人材、資本、創業者を引き付け始めています。物理世界にAIの最先端を拡張する技術の基本要素は同時に成熟しており、過去18か月間の進展は、これらの分野がすぐに各自のスケーリング段階に入ることを示しています。
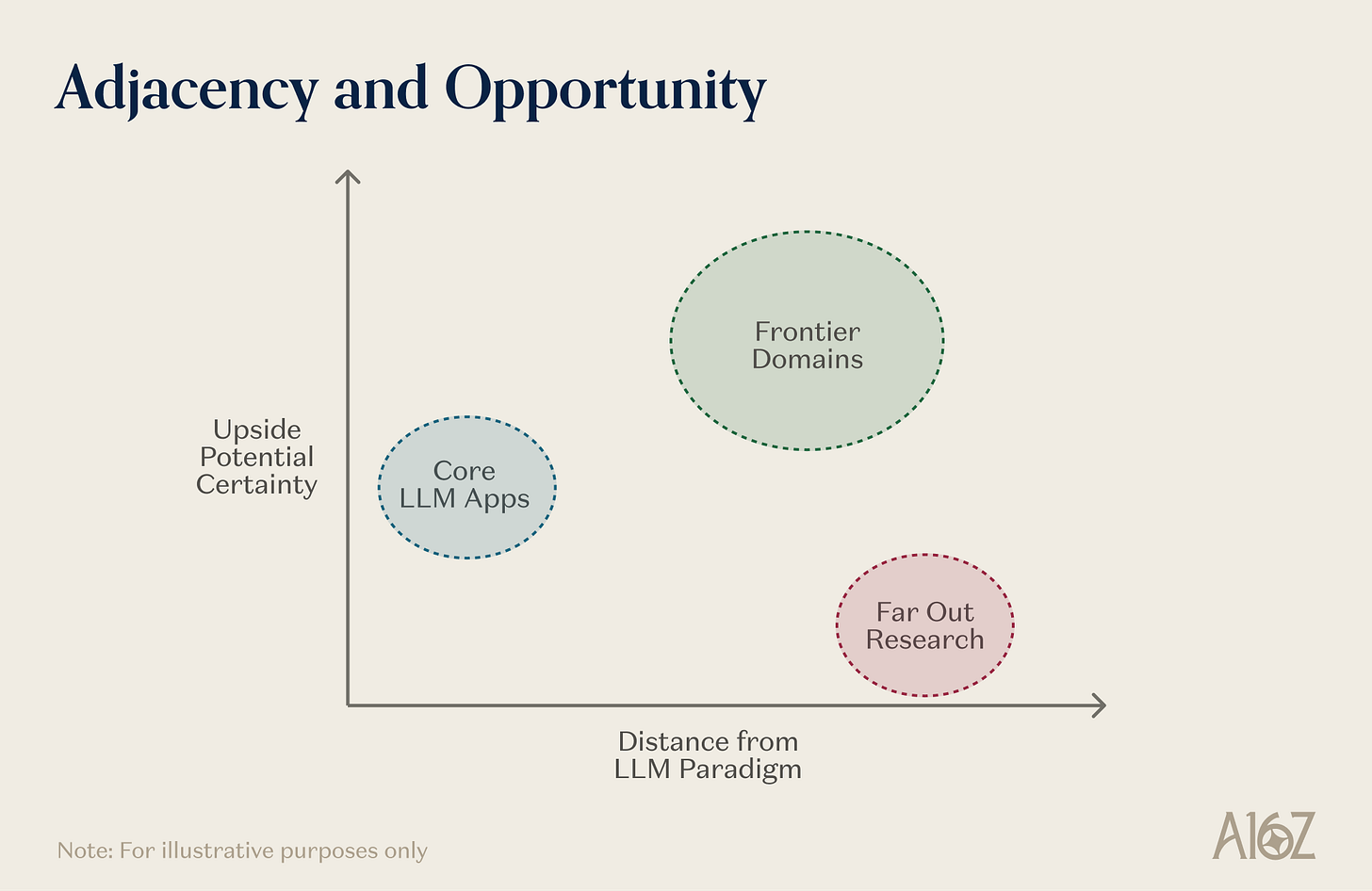
どんな技術パラダイムでも、現在の能力と中期の潜在能力の間の最大の差は、しばしば2つの特徴を持っています:まず、現在の最前線を駆動する同じスケーリングリターンを享受できること、そして次に、主要なパラダイムから一歩離れた距離があること—それは基盤インフラストラクチャと研究エネルギーを引き継ぐには近すぎ、実際の追加作業が必要とされるほど遠すぎるという位置です。
この距離自体には、二重の役割があります:それは迅速に追随できる者に対する要塞を自然に形成し、また、情報がより少なく、より混雑していない問題領域を定義し、したがって新しい能力が浮かび上がる可能性が高くなります—それだけでなく、まだ捷径が踏まれていないためです。

注:現在の AI パラダイム(言語/コード)と隣接する先進システムの関係の概念図
今日、この説明に合致するのは、3つの領域があります:機械学習、自律科学(特に材料科学や生命科学)、新しい人間と機械のインタフェース(脳-機械インタフェース、無声音、神経ウェアラブル、デジタル嗅覚などの新しい感覚チャネルを含む)。
これらは完全に独立した取り組みではありませんが、主題としては「物理世界の先端システム」の1つです。これらは共通の基本的原語を共有しています:物理学的動学学習表現、身体活動指向のアーキテクチャ、シミュレーションおよび合成データインフラストラクチャ、拡張される感覚チャネル、およびクローズドループのエージェント配置。これらは異分野のフィードバック関係で相互に強化し合います。また、変革の可能性が最も高い場所でもあります−モデル規模、物理的展開、新しいデータ形態の相互作用から派生します。
本文では、これらのシステムをサポートする技術的原語を整理し、なぜこれらの3つの領域が先端の機会を象徴し、お互いを強化する方法を提案し、AIを物理世界に推進する構造的なフライホイールを構築するか説明します。
5つの基本的な原語
具体的な応用を見る前に、これらの先進システムが共有する技術的基盤を理解します。AIを物理世界に推進するのは、主に5つの主要な原語に依存しています。これらの技術は任意の特定の適用分野に独占されるものではなく、それらは構成要素です−AIを物理世界に拡張するシステムを構築できるものです。これらの技術が同期して成熟することが、今この瞬間が特別である理由です。

注:物理AIをサポートする5つの基本的な原語
原語1:物理学的動学の学習表現
最も基本的な原語の1つは、物理世界の行動を圧縮し、一般的な学習表現を獲得することです−物体の運動、変形、衝突、応力への反応など。このレイヤーがないと、各物理AIシステムは自分自身の分野の物理法則をゼロから学ばなければなりませんが、誰もがそのコストを負担できません。
いくつかのアーキテクチャの派閥が、異なるアプローチでこの目標に向かっています。VLAモデルはトップダウンアプローチを取っています:事前トレーニングされたビジョン-言語モデル−このようなモデルは既に物体、空間関係、言語の意味理解を備えています−それらの上に動作デコーダーを追加し、運動制御命令を出力します。
重要な点は、世界を「見る」ことと「理解する」ことの巨額のコストが、インターネットスケールの画像テキスト事前トレーニングによって薄められることです。Physical Intelligence の π₀、Google DeepMind の Gemini Robotics、NVIDIA の GR00T N1 は、このようなアーキテクチャをますます大規模に検証しています。
WAM モデルは下からアプローチします:インターネットスケールのビデオで事前トレーニングされたビデオ拡散 Transformer に基づき、豊富な物理学の先行知識(オブジェクトの落下方法、隠され方、力がかかった後の相互作用方法)を継承し、この先行知識とアクション生成を結合します。
NVIDIA の DreamZero は、ゼロショット汎化を新しいタスクと環境に展示し、少量の適応データで人間のビデオデモンストレーションからの跨オントロジー転送が可能であり、実世界での汎化能力が意味のある向上を遂げました。
第3の経路は、将来の方向を判断する上で最も示唆に富むかもしれません。この経路は、事前トレーニングされた VLM とビデオ拡散のバックボーン全体をスキップします。Generalist の GEN-1 は、ゼロからトレーニングされたネイティブの具現基本モデルであり、50万時間を超える実際の物理相互作用データを主に日常的な操作タスクを実行する人々から低コストのウェアラブルデバイスを通じて収集しました。
これは、標準的な意味での VLA でもありません(ビジュアル-言語バックボーンは微調整されていません)、WAM でもありません。これは、物理的相互作用のために特別に設計された基本モデルであり、ゼロから学習し、インターネットの画像、テキスト、ビデオの統計的法則を学ぶのではなく、人間と物体の接触の統計的法則を学びます。
World Labs のような企業が行っている空間知能には、この原語が価値があります。なぜなら、VLA、WAM、およびネイティブの具現モデルが共通して持つ欠点を補完するからです:いずれもシーンの3次元構造を明示的にモデリングしていません。
VLA は、画像テキスト事前トレーニングから継承した2Dビジュアル特徴を持っています。WAM は動学をビデオから学び、ビデオ自体は3Dの2D投影です。ウェアラブルセンサーデータから学習したモデルは力学と運動学を捉えることができますが、シーンのジオメトリを捉えることはできません。空間知能モデルはこの欠点を補うことができます。——物理環境の完全な3D構造を再構築し、その推論を行うことを学習する:幾何学、照明、隠蔽、オブジェクト間の関係、空間配置。
各経路の収束そのものが重要です。VLMから継承された表現、ビデオによる共同トレーニングから学習された表現、または物理的相互作用データからネイティブで構築された表現であっても、基礎となる原語は同じです:圧縮された移植可能な物理世界の振る舞いモデル。
これらの表現が取り込めるデータの世界は非常に巨大であり、ほとんどが未知のままです。インターネットビデオやロボットの軌跡だけでなく、ウェアラブルデバイスが着実に収集を開始している大規模な人間の身体経験データが含まれます。同じセットの表現は、タオルを折るロボット、自律研究室での反応結果の予測、運動皮質のグリップ意図を解釈する脳神経デコーダーにサービスを提供できます。
原語2: 具体的アクション志向アーキテクチャ
物理的表現だけでは不十分です。「理解」を信頼性のある物理的アクションに翻訳するには、いくつかの関連する問題を解決するアーキテクチャが必要です:高レベルな意図を連続した動き指示にマッピングする、長いアクションシーケンスで一貫性を保つ、リアルタイムの遅延制約の下で実行する、および経験に基づいて継続的に向上する。
デュアルシステムの階層アーキテクチャは、複雑な身体的タスクの標準設計となっています:遅くて強力な視覚言語モデルがシーン理解とタスク推論を担当(System 2)、それに、リアルタイム制御を担当する速くて軽い視覚運動戦略(System 1)が追加されます。GR00T N1、Gemini Robotics、FigureのHelixは、この経路の変種を採用して、「大規模モデルによる豊富な推論」と「物理的タスクにおけるミリ秒単位の制御頻度の要求」との根本的な緊張を解消しています。一方、Generalistは、別の経路を取り、「共鳴的推論」を使用して思考とアクションを同時に行います。
アクション生成メカニズム自体も急速に発展しています。π₀が開拓した、フローに基づくマッチングと拡散に基づくアクションヘッドは、スムーズで高周波の連続したアクションを生成するための主流の手法となり、言語モデリングからの離散的なトークン化を置き換えました。このような手法は、アクション生成を画像合成に似たノイズ除去プロセスとして扱い、生成された軌跡は物理的により滑らかで、誤差蓄積に対してより堅牢であり、自己回帰トークン予測よりも優れています。
ただし、アーキテクチャレベルで最も重要な進展は、強化学習を事前トレーニングされたVLA(視覚言語アーキテクチャ)に拡張することかもしれません――デモンストレーションデータでトレーニングされた基本モデルは、自己練習によって引き続き改善され、繰り返し練習と自己修正によってスキルを磨く人間のように。Physical Intelligenceのπ*₀.₆の作業は、この原則を最も明確にスケーラブルに示したものです。彼らの手法はRECAP(Advantage-Conditioned Policy Experience and Correction Reinforcement Learning)と呼ばれ、模倣学習単独では扱えない長いシーケンスの信用割り当ての問題を解決しています。
もしロボットがイタリアンコーヒーメーカーのハンドルをわずかに斜めにつかんだ場合、失敗は直ちに現れるわけではありません。数歩進んで挿入した後に初めて露呈される可能性があります。模倣学習には、この失敗をさかのぼって最初のつかみに帰属させるメカニズムがないが、RLにはあります。RECAPは、任意の中間状態からの成功確率を推定する価値関数をトレーニングし、その後、VLAに高い利得のアクションを選択させます。重要なのは、これに、デモンストレーションデータ、ポリシー自己経験、実行中の専門家遠隔操作からの修正といった多様なヘテロジニアスデータが同じトレーニングパイプラインに統合されていることです。
この手法の結果はRLがアクション領域における展望にとって良いニュースです。π*₀.₆は、未知の50種類の衣類をリアルな家庭環境で重ね、信頼性のある紙箱を組み立て、専門のマシンでイタリアンコーヒーを作り出し、数時間にわたって人間の介入なしに連続して実行します。最も難しいタスクでも、RECAPは純粋な模倣のベースラインに比べてスループットを倍以上にし、失敗率を半分以上減らしました。このシステムは、RL後のトレーニングが模倣学習では得られない性質の変化行動をもたらすことも証明しています:より滑らかなリカバリアクション、より効率的なグラブストラテジー、デモンストレーションデータには存在しない適応的な修正など。
これらの利益は1つを示しています:GPT-2 から GPT-4 に大規模モデルをスケーリングする際の計算力の動きが、具象化された領域で始動し始めていること——ただし、現在はより早期の位置にあり、行動空間は連続的で高次元であり、物理世界の容赦のない制約に直面しなければならない。
プリミティブ3:スケーリングインフラとしてのシミュレーションと合成データ
言語領域では、データの問題はインターネットによって解決されました:自然発生し、無料で入手可能な兆個のトークン化されたテキスト。一方、物理世界では、この問題ははるかに難解です——これは今や共通認識となり、最も直接的なサインは物理世界のデータプロバイダのスタートアップ企業が急速に増加していることです。
現実世界のロボット軌跡の収集コストは高く、スケーリングにはリスクが伴い、多様性は限られています。言語モデルは10億回の対話から学習できますが、ロボットは(一時的に)10億回の物理的相互作用を持つことはできません。
シミュレーションと合成データ生成はこの制約を克服するためのインフラストラクチャ層であり、その成熟が物理世界の AI が今日、5年前ではなく加速する主要な理由の1つです。
現代のシミュレーションスタックは、物理ベースのシミュレーションエンジン、光線追跡に基づく写実的なレンダリング、プログラムによる環境生成、およびシミュレーション入力による写真レベルのビデオ生成を組み合わせた世界のベースモデルです——後者は sim-to-real のギャップを埋める役割を果たします。このパイプライン全体は、リアルワールドからのニューラル再構築(スマートフォン1台でのみ可能)から始まり、物理的に正確な3Dアセットで埋められ、自動的に注釈付けされた大規模合成データ生成までが含まれます。
シミュレーションスタックの改善の意味は、それが物理 AI を支える経済仮定を変えることです。物理 AI のボトルネックが「実データの収集」から「多様な仮想環境の設計」に移動すると、コストカーブは崩れます。シミュレーションは、計算力の拡張によって、人的労力や物理ハードウェアなしで機能します。これは、物理 AI システムのトレーニングの経済構造を変革し、インターネットテキストデータが言語モデルのトレーニングに対して行った改革と同様の意味であり、シミュレーションインフラへの投資はエコシステム全体を大きく支配します。
しかし、シミュレーションはロボットの原語だけではありません。同じインフラストラクチャセットは、自律科学(実験装置のデジタルツイン、合成反応環境の先行び筛選用シミュレーション)、新しいインターフェイス(BCI デコーダのトレーニング用シミュレーションニューラル環境、新しいセンサのキャリブレーション用合成感覚データ)、および他の AI と物理世界とのやり取りの分野にも役立ちます。シミュレーションは物理世界 AI の汎用データエンジンです。
プリミティブ4:感覚チャネルの拡張
物理世界で情報を伝達する信号は、視覚や言語よりもはるかに豊かです。触覚は、材料の特性、グリップの安定性、接触ジオメトリなど、カメラでは捉えられない情報を伝達します。神経信号は、どんな既存の人間と機械のインターフェースでもまったく足りない帯域幅で、運動意図、認知状態、知覚経験をエンコードします。亜音波筋活動は、音声が生成される前に言語の意図がエンコードされます。第四のプリミティブは、AIがこれら以前にアクセス困難だったモードの感覚経路を迅速に拡張することです。これは研究だけでなく、消費者向けデバイス、ソフトウェア、およびインフラのエコシステム全体からもたらされています。
Caption: Expanding AI sensory channels from AR, EMG to brain-machine interfaces
最も直感的な指標は、新しいカテゴリのデバイスが登場することです。最近、ARデバイスは体験と形態の両面で大幅に向上しています(このプラットフォームで消費者および産業用途のアプリケーションを展開している企業もあります);音声優先のAIウェアラブルは、言語型AIにより完全な物理世界の文脈を提供し、これらのデバイスはユーザーとともに物理環境に入り込んでいます。
長期的には、脳インタフェースがより包括的なインタラクションモードを開く可能性があります。 AIによる計算方法の変革は、人間と機械のインタラクションを大幅に向上させる機会を生み出し、Sesameなどの企業は新しいモードとデバイスを構築しています。
このような主流のモードの一つである音声は、新興のインタラクション方法に追い風をもたらしています。Wispr Flowのような製品は、音声を主要な入力方法として推進しており(情報密度が高く、天然の利点があるため)、無音音声インタフェースの市場状況も改善されています。無音音声デバイスは、複数のセンサーを使用して舌と声帯の動きを捉え、無音の言語認識を行います—これは音声よりも情報密度が高い人間と機械のインタラクションモードを示しています。
脳機インタフェース(侵襲的および非侵襲的)は、さらに先進的な分野を代表し、そのビジネスエコシステムは引き続き前進しています。シグナルは臨床での検証、規制承認、プラットフォーム統合、機関資本の統合点に登場します—これは数年前には純粋に学術分野に属していた技術カテゴリーです。
触覚知覚は具体的なAIアーキテクチャに取り入れられつつあり、ロボティクスの一部のモデルでは触覚を明示的に取り込んでいます。嗅覚インタフェースは、実際のエンジニアリング製品になりつつあります:ウェアラブル嗅覚ディスプレイは、マイクロスケールの臭気発生器とミリ秒単位の応答を使用し、ハイブリッドリアリティアプリケーションでデモされています;嗅覚モデルは、化学工程監視に使用される視覚AIシステムと組み合わされるようになっています。
これらの展開の共通のパターンは、極限時にお互いに収束することです。ARグラスは、ユーザーと物理環境の相互作用を生成し続けます;EMGリストバンドは、人間の運動意図を統計的パターンとしてキャプチャします;無音音声インタフェースは、亜音波発音から言語出力へのマッピングをキャプチャします;BCIは、最高解像度で神経活動をキャプチャします;触覚センサーは、物理的操作の接触力学をキャプチャします。新しい各デバイスは、同時にデータ生成プラットフォームでもあり、さまざまなアプリケーション領域の基礎となるモデルを養います。
運動意図データを推測するために EMG を使用してトレーニングされたロボットと、リモート操作データだけを使用してトレーニングされたロボットは、それぞれ異なるグラスプ戦略を学習します。亜音声コマンドに応答する実験室インターフェースと、キーボード制御の実験室は、科学者と機械の相互作用方法を完全に異なるものにもたらします。高密度BCIデータによってトレーニングされた神経デコーダーは、他のどのチャネルも得られない運動計画表現を生成することができます。
これらのデバイスの普及は、物理的AIシステム向けのトレーニングフロンティアの拡大を促進し、この拡大の大部分は、学術研究所だけでなく、資本に乏しい消費財企業によって推進されています。これは、データフライホイールが市場の採用率に合わせて拡大していることを意味します。
原語五:クローズドループエージェントシステム
最後の原語は、主にアーキテクチャのレベルです。これは、知覚、推論、行動計画を持続的で自律的なクローズドループシステムとして組み合わせ、長期間にわたり人間の介入なしで機能するというものです。
言語モデルでは、この進化に相当するものは、エージェントシステムの台頭です。複数段階の推論チェーン、ツールの使用、自己修正プロセスにより、モデルは単一の質問回答ツールから自律的な問題解決者へと移行しました。物理世界でも、同様の変革が起こりつつありますが、はるかに厳しい要求があります。言語エージェントが間違ると、コストなしに戻ることができますが、物理的エージェントが瓶をこぼすと、元に戻すことができません。
物理的世界のエージェントシステムには、それをデジタル版と区別する3つの特性があります。
第一に、それらは実験あるいは実行のクローズドループに埋め込まれている必要があります。生データストリームや物理状態センサー、実行プリミティブに直接接続し、推論を物理現実に落とし込みます。第二に、それらは長いシーケンスの持続性が必要です。メモリ、トレースバック、セキュリティ監視、リカバリ動作を含め、複数の実行サイクルをつなぎ合わせ、各タスクを独立したエピソードとして扱わないようにします。第三に、それらはクローズドループ適応が必要です。物理的結果に応じて戦略を修正し、テキストフィードバックだけでなく物理的フィードバックに基づいています。
この原語は、単一の機能(良好なワールドモデル、信頼性の高いアクションアーキテクチャ、豊富なセンサースイート)を物理世界で自律的に実行できる完全なシステムに統合します。これは統合レイヤーであり、その成熟度は、後述の3つの応用領域が単なる研究デモではなく、実世界展開として機能する前提条件として存在しています。
3つの領域
上記の原語は、一般的な有効化レイヤーであり、それ自体が最も重要な応用がどこに育つかを指定していません。多くの領域は、物理的アクション、物理的測定、または物理的知覚に関与しています。 「フロンティアシステム」と「既存システムの単なる改良版」とを区別するのは、その領域内のモデル能力向上とスケーリングインフラの複利効果の程度です。性能が向上するだけでなく、以前に達成できなかった新しい機能が浮かび上がってくるのです。
ロボット、AI ドリブンサイエンス、新しいタイプの人間とのインターフェースは、この複利効果が最も強い3つの領域です。それぞれが独自の方法で原語を組み立て、それぞれが現在の原語が解消しようとしている制約に阻まれており、またそれぞれが運用中に副生的に構造化された物理データを生成します。このデータは逆に元の原語を向上させ、フィードバックループを形成し、システム全体を加速させます。これらは物理的 AI の領域で唯一注目すべきものではありませんが、最先端の AI 能力と物理的現実との相互作用が最も濃密な場所であり、現在の言語/コードパラダイムから最も遠いため、新しい能力が出現する空間が最も大きい場所です。同時に、これらは非常に補完的であり、その恩恵を受けることができる場所です。
ロボット
ロボットは、文字通り最も物理的な AI の具体化です:AI システムが物質世界をリアルタイムで知覚し、推論し、物理的行動を起こす必要があります。また、各原語が圧力テストされます。
一般的なロボットがタオルを折り畳む場合、どれだけの作業を行う必要があるか考えてみてください。可変形材料が力を受けた場合の振る舞いについて学習した表現が必要ですが、これは言語の事前トレーニングでは提供されません。また、高レベルの命令を20 Hz以上の制御頻度での連続運動命令シーケンスに変換するアクションアーキテクチャが必要です。
何百万回も実際のタオル折りデモを収集した人は誰もいないため、シミュレーション生成のトレーニングデータが必要です。滑りを検知し、握り力を調整するための触覚フィードバックが必要です。視覚は、一度に安定したグリップと失敗しているグリップを区別できません。失敗した場合にそれを認識し、回復する能力を持つクローズドループコントローラも必要です。メモリートレースを盲目的に実行するのではなく、誤りを検知し、修正する必要があります。
図説:ロボットタスクは5つの基本原語を同時に呼び出す
これが、ロボットが前衛システムであり、成熟したエンジニアリング学科よりも優れたツールである理由です。これらの基本原語は、既存のロボット機能を改良するのではなく、以前は狭く制御された産業環境外で達成できなかった操作、運動、および相互作用のカテゴリを解除します。
過去数年間、前衛の進歩が顕著です — 以前にも触れました。第1世代 VLA は、基本モデルがさまざまなタスクを持つロボットを制御できることを証明しました。アーキテクチャの進歩は、ロボットシステムの高位推論と低位制御を統合しました。エッジサイドの推論が実現可能になり、オントロジー間の移行により、モデルは限られたデータで新しいロボットプラットフォームに適応できます。残された中核的な課題は、スケーラビリティの確保であり、これは依然として展開のボトルネックです。95% の成功率毎に、10段階のタスク連鎖でわずか60% であり、実稼働環境でははるかに高い要求があります。RL トレーニング終了後には、この領域が拡張段階に必要な能力と堅牢性の閾値に到達するのを支援する可能性が非常に大きいです。
これらの進展は市場構造に影響を与えています。数十年にわたるロボティクス産業の価値は、機械システム自体に蓄積されてきました。機械はまだ技術スタックの重要な部分ですが、学習戦略がより標準化されるにつれて、価値はモデル、トレーニングインフラストラクチャ、データフライホイールに移行していきます。ロボットは同時に上記の原語に還元します:すべての現実世界の軌跡は世界モデルのトレーニングデータを改善し、各展開の失敗はシミュレーションカバレッジの欠如を露呈し、各新しい本体のテストは事前トレーニングに使用できる物理的経験の多様性を拡大します。ロボットは原語の最も厳格な消費者であり、それらの最も重要な改善信号源の1つでもあります。
自己主導型サイエンス
もしロボットが「リアルタイムの物理的アクション」で原語をテストするものだとすれば、自己主導型サイエンスは若干異なるものをテストします。それは因果関係の複雑な物理システムに対する持続的な多段階推論であり、時間枠は数時間または数日で、実験結果は解釈されコンテキスト化され、戦略が修正されるために使用されます。
Figure Caption: 自己主導型サイエンス(AIサイエンティスト)が5つの基本原語を統合する方法
AI駆動科学は、原語の組み合わせにおいて最も包括的な分野です。自動運転ラボ(SDL)は、何を予測するかを知るために物理化学力学的表現を学びます。液体の移動、サンプルの配置、分析機器の操作を行うために具体的なアクションを実行する必要があります。候補となる実験を事前にスクリーニングし、希少な機器の時間を割り当てるためにシミュレーションを使用する必要があります。さらに、結果を特徴付けるために光スペクトル、クロマトグラフィー、質量分析などの拡張されたセンシング能力が必要です。
どの他の分野よりも、この関連性を持ち合わせたエージェント配列原語が必要です:未介入の多段階の「仮説-実験-分析-修正」ワークフローを維持し、各ラウンドで明らかにされた情報に基づいて戦略を調整します。
他の分野では、これらの原語をこのように深く利用することはありません。これが自己主導型サイエンスが先端の「システム」であり、ソフトウェアの実験室自動化よりも優れている理由です。Periodic LabsやMedraなどの企業は、材料科学や生命科学分野で科学的推論能力と物理的検証能力を統合し、科学的反復を実現し、実験トレーニングデータを提供しています。
このようなシステムの価値は、直感的に明らかです。従来の材料発見は、概念から商品化まで数年かかりますが、AIによるワークフローの加速により、このプロセスを大幅に短縮できる理論上の可能性があります。主要な制約は、仮説の生成(基本モデルは支援されているため)から製造と検証(物理機器、ロボット実行、閉ループ最適化が必要)に移行しています。この壁に向かってSDL は前進しています。
自己主体的もう一つの重要な特徴 — あらゆる物理世界システムで成り立つ — は、それがデータエンジンとしての役割を果たすことです。SDL が実行される各実験は、科学的結果だけでなく、物理的に基づいた、実証されたトレーニングシグナルを生成します。
特定の条件下でポリマーがどのように結晶化するかに関する一回の測定は、世界のモデルが材料力学を理解するのを豊かにします。検証済みの合成経路は、物理的推論のトレーニングデータとなります。特性が表徴された失敗は、インテリジェントシステムに予測がどこで失敗したかを教えます。AI 科学者が実験から得るデータは、インターネットテキストやシミュレーションの出力とは異なります — それは構造化され、因果関係があり、実証されています。これこそが物理的推論モデルが最も必要とし、他からは提供されない種類のデータです。自律科学は、物理世界を直接構造化された知識に変換し、物理 AI エコシステム全体を向上させるための経路です。
新しいタイプのインターフェース
ロボットは AI を物理的アクションに拡張し、自律科学は AI を物理研究に拡張します。新しいタイプのインターフェースは、人工知能と人間の知覚、感覚体験、身体信号を直接結合する — AR メガネ、EMG リストバンド、埋め込み式脳-機械インタフェースまでのデバイスを横断します。
このカテゴリを結びつけているのは、個々の技術ではなく、共通の機能です: 人間の知能と AI システムとの間のチャネルの帯域幅とモードを拡張し、これにより物理 AI を構築するために直接使用できる人間-世界の相互作用データを生成します。

図説: AR メガネから脳-機械インタフェースまで、新しいタイプのインターフェースの系統
主流のパラダイムからの距離は、この分野の課題であり、また潜在能力でもあります。言語モデルは概念的にこれらのモードを知っていますが、無声音声の動きパターン、嗅覚受容体結合の幾何学的構造、または EMG シグナルの時間的力学については天然に馴染んでいません。
これらの信号の表現をデコードすることは、拡張され続ける感覚チャネルから学ばなければなりません。多くのモードにはインターネット規模の事前トレーニングコーパスがなく、データは通常インタフェース自体からのみ生成されます — これは、システムとそのトレーニングデータが協調進化していることを意味し、これは言語 AI には対応しない特性です。
この分野の最近の進展は、AI ウェアラブルが消費財として急速に台頭していることです。AR メガネはおそらくこのカテゴリの最も目立つ例であり、音声や視覚を主要な入力とする他のウェアラブルも同時に登場しています。
この消費者向けデバイスエコシステムは、AI が物理世界に拡張される新しいハードウェアプラットフォームを提供するだけでなく、物理世界のデータインフラとなっています。AI メガネを着用している人は、物理環境でのナビゲーション方法、物体操作、世界とのやり取りについての第一人称ビデオストリームを継続的に生成できます。他のウェアラブルデバイスは、生体認証データや動作データを継続的にキャプチャします。AI ウェアラブルの普及率は、分散型の物理世界データ収集ネットワークに変わりつつあり、これまでにないスケールで人間の物理的経験を記録しています。
消費者向けデバイスとしてのスマートフォンの規模を考えてみてください — 同等の規模で新しいカテゴリの消費者向けデバイスは、コンピューターが新しいモードで世界を知覚し、AI と物理世界とのやり取りに大きな新しい経路を開いています。
脳-機械インタフェースはさらに先鋭的です。Neuralink は複数の患者にインプラントされ、手術ロボットとデコードソフトウェアがイテレーションされています。Synchron の血管内ステントロードは、麻痺患者がデジタルや物理的環境を制御するのに使用されています。Echo Neurotechnologies は、高分解能の皮質音声デコーディングに基づいた言語回復用の BCI システムを開発しています。
Nudge のような新興企業も、新しい脳インタフェースと脳との相互作用プラットフォームを構築するために人材と資本を集めています。研究段階の技術のマイルストーンにも注目すべきです:BISC チップは、65536 電極のワイヤレス神経記録を1つのチップでデモンストレーションしています;BrainGate チームは、運動皮質から内部言語をデコードしています。
AR メガネ、AI ウェアラブル、サイレント音声デバイス、埋め込み式脳-機械インタフェースを貫く主要テーマは「それらがすべてインタフェースであること」だけでなく、それらが共に人間の物理的経験と AI システムの間に、帯域幅を増加させるスペクトルを構成していることです — このスペクトル上の各ポイントは、本文の3つの主要分野の背後にある基本的な原則を支えています。
数百万人のAIメガネユーザーからトレーニングされた高品質の第一人称ビデオを使用したロボットは、オペレーション先天知識を習得し、フィルタリングされたリモートオペレーションデータセットでトレーニングされたロボットとは全く異なります。亜音波コマンドに応答する実験室のAIと、キーボードコントロールの実験室のAIは、遅延とスムーズさにおいてまったく異なります。高密度BCIデータでトレーニングされた神経復号器は、他のチャネルでは得られない運動計画表現を生成します。
新しいタイプのインタフェースは、感覚チャネル自体を拡張するメカニズムです — これにより、物理世界とAIの間に以前に存在しなかったデータチャネルが開かれます。そして、この拡張は消費者の採用に従ってデータのスプリントが加速することを意味します。
物理世界のシステム
ロボット、自律科学、新しいインターフェースを同じプリミティブの組み合わせから派生した先端システムの異なるインスタンスと見なす理由は、お互いにエンエーブルし、複利が生じるからです。
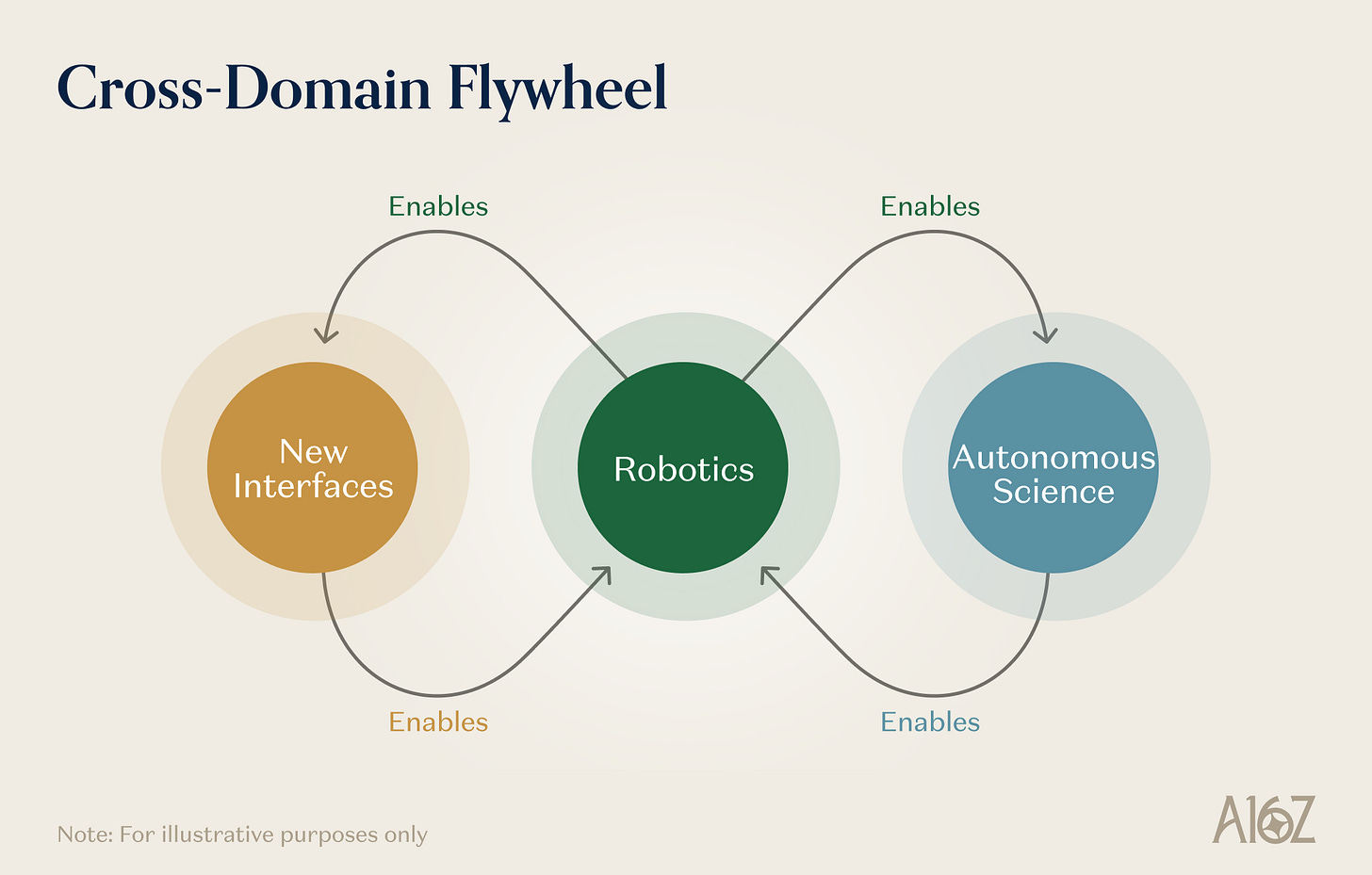
図説: ロボット、自律科学、新しいインターフェース間のフィードバックループ
ロボットが自律科学をエンエーブルします。 自動運転ラボは、本質的にはロボットシステムです。汎用ロボットのための操作能力 - 機敏なグリップ、液体処理、精密な位置決め、複数段階のタスク実行 - は、直接ラボの自動化に移植できます。ロボットモデルが汎用性と頑強性の面で進歩するたびに、SDL が自発的に実行できる実験プロトコルの範囲が拡大します。ロボット学習の進展ごとに、自律実験のコストが低下し、スループットが向上します。
自律科学がロボットをエンエーブルします。 自動運転ラボが生成する科学データ - 検証された物理的測定、因果実験結果、材料特性データベース - は、ワールドモデルおよび物理推論エンジンが必要とする構造化されたトレーニングデータを提供できます。さらに、次世代のロボットが必要とする材料やデバイス(より良いアクチュエータ、より感度の高い触覚センサー、より高密度なバッテリーなど)は、材料科学の成果そのものです。材料学の自律的な発見プラットフォームは、ロボット学習システムの実行を改善するハードウェアレイヤーに直接影響します。
新しいインターフェースがロボットをエンエーブルします。 AR デバイスは、「人間が物理的環境をどのように知覚し、やり取りするか」のデータを収集するためのスケーラブルな手段です。脳インタフェースは、人間の運動意図、認知計画、感覚処理に関するデータを生成します。これらのデータは、特に人間とロボットの協働やリモート操作のタスクに関与する場合に、ロボット学習システムのトレーニングに非常に貴重です。
ここで、先端AIの進歩そのものの性質についてもう少し深く考察します。言語/コーディングの範式は、スケーリング時代においても力強く台頭しています。しかし、物理世界が提供する新しい問題、新しいデータタイプ、新しいフィードバック信号、新しい評価基準はほぼ無限です。AIシステムを物理的現実に載せること - 物体を操作するロボット、合成材料のラボ、生物と物理世界を結ぶインターフェースを介して - 我々は既存のデジタルフロンティアに補完する新しいスケーリング軸を展開し、お互いに改善される可能性が高いです。
図説: 物理AIの各スケーリング軸の相互作用とエマージェンス
これらのシステムは、予測が非常に困難な振る舞いをもたらす可能性があります——「涌現」の定義は、それぞれ独立して理解可能な能力の組み合わせによって初めて現れる能力です。しかし、歴史的なパターンは楽観的です。AI システムが世界との新しいモードとのやり取りごとに得る能力の飛躍——見ること(コンピュータビジョン)、話すこと(音声認識)、読み書きすること(言語モデル)——は、各々の改善の合計をはるかに超えています。物理世界へのシステムの移行は、次のこの種の位相遷移を意味します。この意味では、この論文で議論されているこれらのプリミティブは、現在構築されつつあり、先端の AI システムが物理世界を感知し、推論し、作用させ、物理世界で大きな価値と進歩を開放する可能性があります。
原文リンク
BlockBeats の公式コミュニティに参加しよう:
Telegram 公式チャンネル:https://t.me/theblockbeats
Telegram 交流グループ:https://t.me/BlockBeats_App
Twitter 公式アカウント:https://twitter.com/BlockBeatsAsia