2026年、一般の人々が取引シグナルをキャッチする方法は?

原文タイトル:50個の弱いシグナルを1つの勝利トレードに組み合わせる数学
原著者:Roan、暗号アナリスト
翻訳、解説:MrRyanChi、insiders.bot
はじめに
昨年、トランプ・マスク同窓生マスク交換@Whartonの最初の週に、私は@DakshBigShitと@insidersdotbotを設立しました。ウォートン・スクールの優れた土壌とニューヨークに近い地理的利点のおかげで、私はわずか4か月で数十億ドル規模のヘッジファンドを運営する多くのパートナーと深く交流しました。
その後、香港での創業後、insiders.botは有名になり、私はアジアの量子機関との深い交流を持つ機会を得ました。
この過程で、繰り返し耳にする言葉の1つが「シグナル」でした。
エントリーシグナル、エグジットシグナルなど。このプロセスで、小売業者と機関の間の最大の違いは、情報量でも資金量でもなく、思考枠組みです。小売業者は常に「完璧なシグナル」を見つけようとしますが、機関は何十もの「あまりよくない」シグナルを1つのロープに組み上げる数学エンジンを使用しています。
Binance、OKX、Bitgetなどの取引所が運営するウォレットも、さまざまなシグナル配信コンテンツに早くから参加しています。
さらに、最初に立ち上げられたinsiders.botは「シグナルボット」として登場しました。 当時最も人気のあったv1.2シグナルは、多くのスマートマネーシグナルを集約したシグナルであり、多くのブロックチェーンのエキスパートから賞賛を受けました。市場トレーダーのお気に入りのアラートシステムである@poly_beatsも本質的にはシグナルです。
このRohOnChainの記事は、私が参照した中で「シグナル」フレームを最も明確に説明したものでした。私は時間をかけてこの記事を書き直し、補完し、注釈をつけました。量子的なバックグラウンドがなくても、最初から最後まで理解できるようにしたかったのです。
第1部:存在しない「完璧なシグナル」
私は20年間システマティックトレードの分野で活動してきたヘッジファンドのパートナーとお話ししているときに、数か月間考え込む一言を耳にしました。
その日、彼は私の向かいに座って、私たちが議論している戦略を見つめながら、静かに言いました:
「あなたは常に、永遠に正しい唯一のシグナルを探そうとしています。しかし、そのようなものは実際に存在しません。本当に勝てる取引所は、多くの『やや正確な』シグナルを正しく組み合わせることができるチームです。」
彼が説明したこのものは、量的分野には一つの専門的で非常に抽象的な言葉があります:
アルファ組合(Alpha Combination)。
このフレームワークは一つの分岐点です。それは、安定した利益を継続的に上げることができる機関と、「方向性は明らかに当たっているのに依然として損失を出してしまう」小売業者とを厳密に分けています。
この記事を読むと、次の5つのことが理解できます:
1. 50の弱いシグナルを組み合わせることが、1つの強いシグナルを遥かに凌駕する理由
2. 「アクティブ・マネジメントの基本法則」とは何か
3. 機関が、どの11のステップで低品質なシグナルを高勝率の戦略に変えるのか
4. なぜ、あなたが方向性を間違えずに損失を出すのか
5. このシステムをPolymarketで完璧に適用する方法
本当に取引の優位性を築きたい場合は、どのセクションも飛ばさないでください。このフレームワークは、5つの部分をつなぎ合わせて見ることで、本当の力を発揮します。
ちなみに、この記事は AI エージェント向けにも最適化されています。あなたのClaude、Manus、または任意のAIに提供して、すぐに独自の量的モデル構築を開始してください。
1.1 信号とは何ですか?
数学に深入りする前に、まず言葉を統一しなければなりません:信号とは具体的に何ですか?
日常生活では、よく「このコインは上昇すると感じる」とか、「トランプ氏は当選すると思っている」と言います。これは見解です。見解は曖昧で主観的であり、正確な戻り検証ができません。
しかし、機関の量的フレームワークでは、信号は将来の価格や確率の変化と統計的に再現可能な関係を持つ測定可能なデータポイントです。
それは3つの条件を満たさなければなりません:
数量化可能性:それは具体的な数字でなければなりません。たとえば、「過去24時間の取引量が3倍に増加しました」というような表現であり、「最近話題になっている人が増えた」という表現ではありません。
方向性:それは価格が上昇するか下落するか、または確率が高まるか低下するかを示さなければなりません。
繰り返し可能性:それは孤立したイベントではなく、過去に複数回出現し、そして毎回出現後、市場が類似の反応を示している必要があります。
たとえば、Binanceで数名の高勝率の大口取引者が連続して買い注文を入れ、いくら買ったかがシグナルです。
たとえば、私たちの @insidersdotbot のv1.2の偏り(スケウ)もシグナルです。
Polymarketの例を挙げると:過去に勝率が70%を超える賢明な取引参加者が、突然マイナーな契約に5万ドル賭けた場合、これは非常に標準的な「マイクロストラクチャーシグナル」です。これは具体的であり(5万ドル)、方向性があります(彼が賭けた選択肢)、そして繰り返し可能です(彼の過去のすべての賭け履歴をバックテストできます)。
シグナルの意味を理解したら、次に考える問題は次のとおりです:あなたのシグナルの正確度はどの程度ですか?
1.2 ICとは?あなたのシグナルの「成績表」
取引をしたことがあるすべての人が経験する瞬間です:あなたの分析が正しかったし、価格も確かに予測した方向に動いていましたが、最終的には損失が出てしまいました。
これは運の問題ではありません。単一のシグナルに依存して取引すると、損失することはほぼ数学的に必然です。なぜそうなるのかを理解することは、次に続くすべての内容の基盤です。
量化研究では、各シグナルには情報係数(Information Coefficient、ICと略されます)と呼ばれる、正確性を測定する指標があります。
ICは、あなたの予測と市場の実際の動向との関連性を測定しています。これはあなたのシグナルの「成績表」と考えることができます。
それでは、ICは具体的にどのように計算されるのでしょうか?一つずつ見ていきましょう。
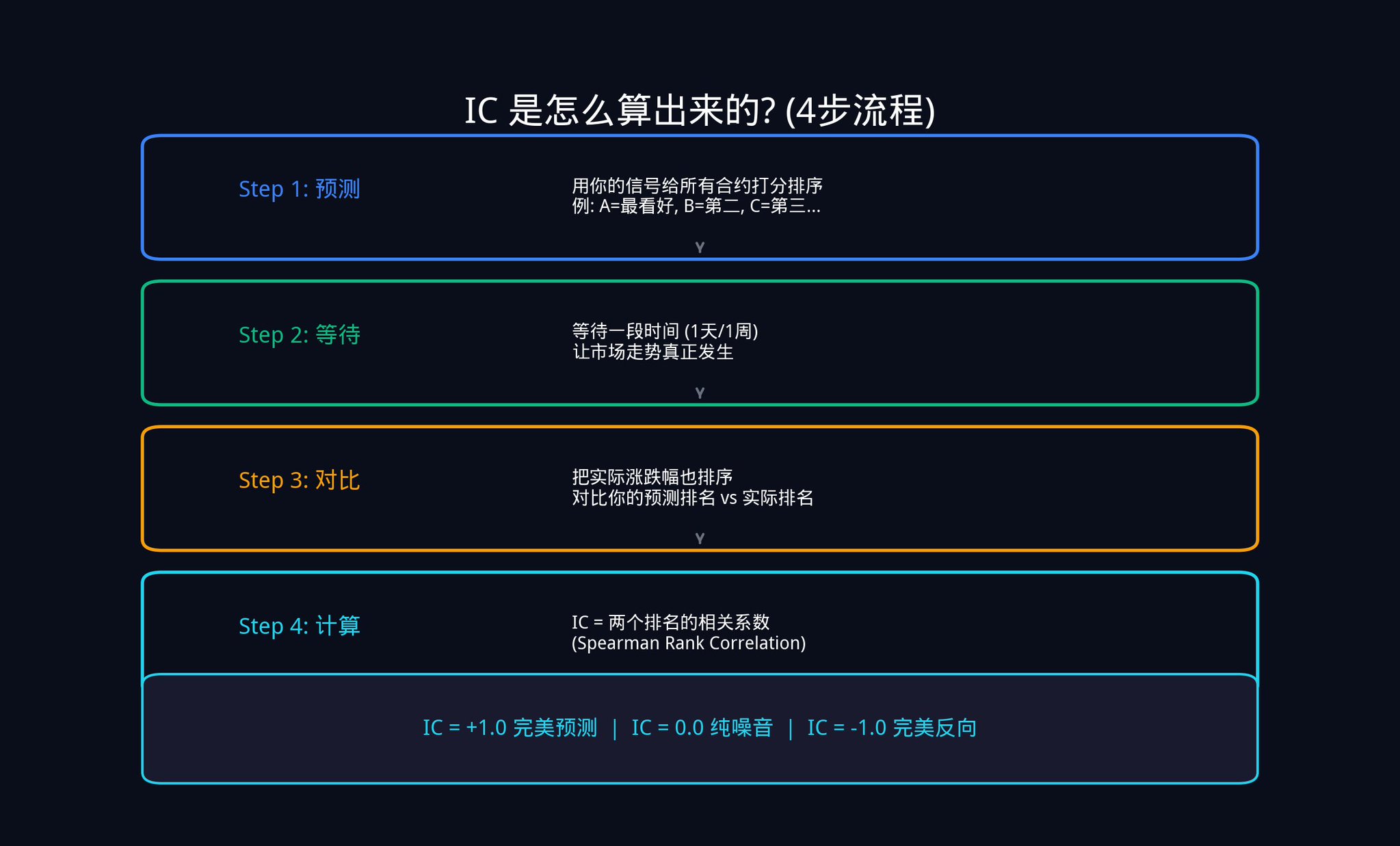
ステップ1:予測。 今日、Polymarket には20個のアクティブな契約があると仮定してください。あなたはシグナルを使用してこれら20個の契約にスコアを付け、順位付けします。契約Aが最も上昇する可能性が高いと予測し、1位にランク付けします。契約Bは2位に、これを続けて20位までランク付けします。
ステップ2:待つ。 1日、1週間、または設定した任意の時間枠だけ待ち、市場の動向が実際に発生するのを許します。
ステップ3:比較。 時間が経過した後、これら20個の契約の実際の価格変動も順位付けします。最も多く上昇したものが1位に、2番目に多く上昇したものが2位になり、これを続けます。
ステップ4:計算。 これで、元々の予測ランキングと実際の結果ランキングの2つの列が手に入りました。計算する必要があるのは、これら2つのランキング間の関連性です。
ここで使用されているのは、スピアマン順位相関係数(Spearman Rank Correlation)という統計学の概念です。
恐ろしいように聞こえますが、実際のロジックは非常に単純です:
・ あなたが予測して1位にランク付けした契約が実際に最も上昇した場合、2番目にランク付けした契約が2位になるなど、予測ランキングと実際のランキングが非常に一致している場合、ICは+1.0に近づきます。
・ 完全に逆の場合(最も上昇すると予測したものが実際には最も下落するなど)、ICは-1.0に近づきます。
・ 一切関係がない場合、ICは0.0であり、あなたのシグナルはサイコロを振ることと同じです。
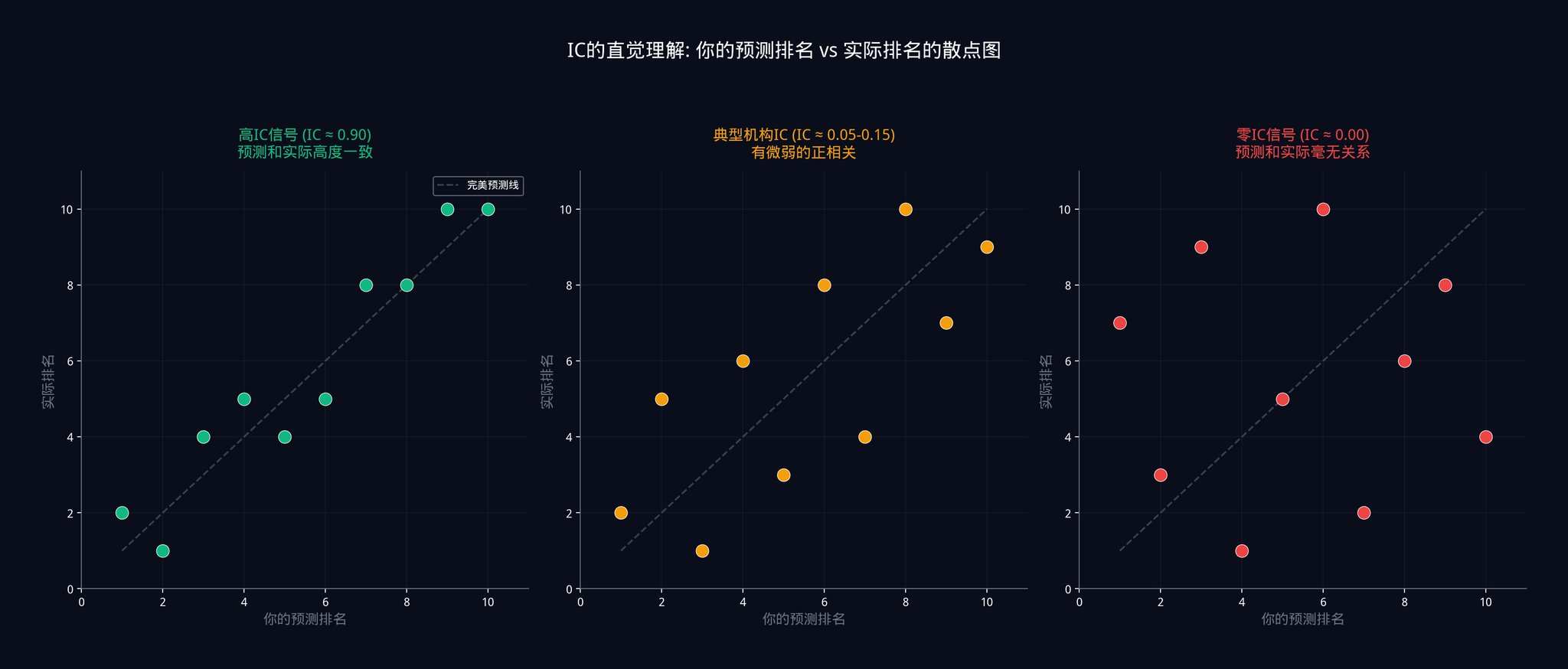
上の図は、3つの異なるICレベルで、予測ランキングと実際のランキングの間の関係を示しています。
左側はICが0.9に近い場合で、点がほぼ対角線上に落ちており、予測と実際が非常に一致していることを示しています。
中央はICが0.05から0.15の間の場合で、点がばらばらに散らばっており、非常に弱い正の相関傾向しかありません。
右側はICが0の場合で、完全にランダムであり、何のパターンもありません。
なぜ数値ではなくランクを使用するのですか?
外れ値に対して順位は敏感ではありません。例えば、ある契約がブラックスワンイベントの影響で500%急上昇した場合、数値を使って相関性を計算すると、この外れ値が結果全体を歪める可能性があります。しかし、順位を使用すると、その契約はただの「1位」になるだけであり、他の契約の順位に影響を与えません。これが機関投資家がピアソン相関係数ではなくスピアマンの順位相関を好む理由です。
実際の操作では、1日分のICだけを計算するのではありません。このプロセスを多くの日(たとえば100日)繰り返し、その後平均値を取ります。この平均値が信号の平均ICです。
それでは、ウォール街のトップトレーディングデスク、数十億ドル規模の資金を利用した信号のICはどのくらいでしょうか?
答え:0.05から0.15の間。
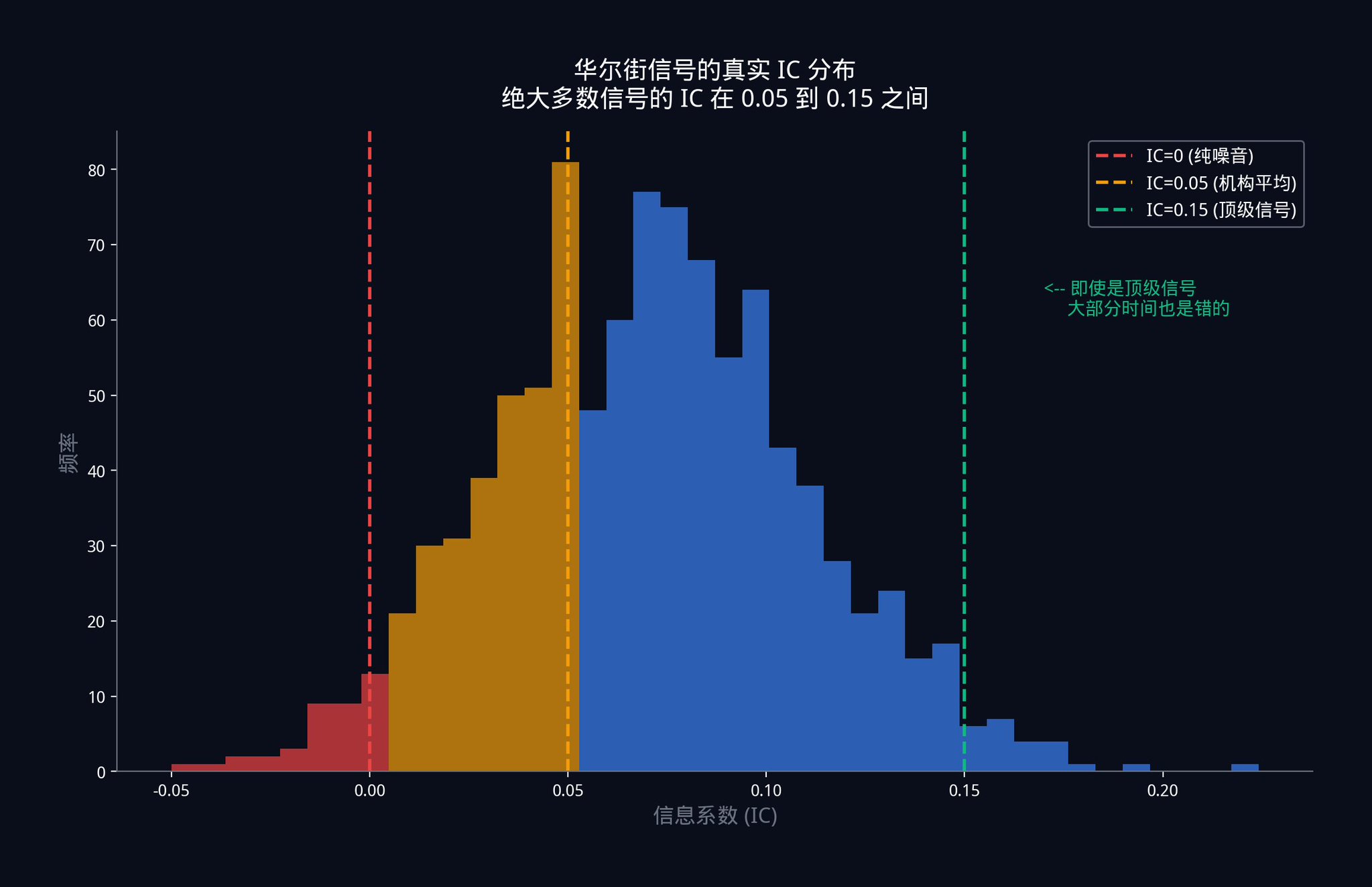
この数字をもう一度見てみてください。機関投資家が使用する最高レベルの単一信号は、ほとんどの場合誤っています。偶発的に間違っているのではなく、ほとんどの時間誤っています。
IC = 0.05 はどういう意味ですか?
これは、あなたの信号と市場の実際の動向との間にわずか5%の関連性しかないことを意味します。散布図を作成すると、点はほとんどランダムに分布しており、非常に微弱な正の傾向しかありません。
これは信号が悪化したわけではありません。これは競争の激しい市場の本質です。強力な利点が発見されると、資金が殺到し、その利点が搾取され、極めて低いレベルに圧縮されるまで続きます。効率的な市場では、0.05のICを安定させることは非常に大きな成果です。
個々の信号が非常に弱い場合、機関はどのようにして利益を上げているのでしょうか?
1.3 機関の秘策:アクティブ・ポートフォリオ管理の基本法則
1994年、量的研究の先駆者であるRichard GrinoldとRonald Kahnは、彼らの著書「Active Portfolio Management」で、資産管理業界全体を変えた公式を提案しました:
IR = IC x √N
この式はアクティブ・マネジメントの基本法則(The Fundamental Law of Active Management)として知られています。

では、これらの3つの文字はそれぞれ何を表しているのでしょうか?
IR(情報比率、Information Ratio) は、あなたのトレーディングシステム全体の「総合的な成績」を示します。リスクを1単位取るごとにどれだけの利益を得られるかを測定します。これは「コストパフォーマンス」指標と考えることができます。IR が高いほど、戦略がより「安定している」と言えます。量的トレーディング業界では、IR が1.0に達すると、最高水準と見なされます。
IC(情報係数、Information Coefficient) は、さきほど1セッションかけて説明したものです:単一信号の平均精度です。
N は、ポートフォリオ内の独立した信号の数です。ここで「独立」という言葉が非常に重要であることに注意してください。なぜかについて詳しく説明します。
この式のコアメッセージは次のとおりです:全システムのパフォーマンス(IR)は、単一信号の精度(IC)に信号数の平方根(√N)を乗じたものです。
それでは、質問です。なぜ平方根なのでしょうか?なぜ N をそのまま乗じないのでしょうか?この質問は非常に重要ですので、ゼロから導くようお手伝いします。
コイントスを想像してみてください。表が出ると1ドルを獲得し、裏が出ると1ドルを失います。
1回しかコイントスをしない場合、結果は完全にランダムです。1ドルを獲得するか、1ドルを失います。
しかし、100回コイントスをする場合はどうでしょうか?合計収益の期待値は0です(表と裏がそれぞれ50回)。しかし、重要なのはボラティリティです。統計学によると、100回の独立したコイントスの総ボラティリティは100ではなく、√100 = 10 となります。
なぜでしょうか?独立したランダムイベントが重なると、そのノイズの一部が相殺されるためです。表と裏が交互に出現し、すべてが一方向に向かうわけではありません。したがって、総ボラティリティが総数より遅く増加します。
さて、この論理を信号の組み合わせに適用してみましょう。N 個の独立した信号があるとしましょう。各信号には微小な前向きの利点があります(IC が0より大きい)。
総収益(すべてのシグナルの利点の合計)は N の線形増加に従って増加します。なぜなら、各シグナルが追加されるたびにわずかな利点が得られるからです。10個のシグナルの総利点は1つのシグナルの 10 倍です。
しかし、総リスク(すべてのシグナルのノイズが重ね合わされる)は √N に従ってのみ増加します。独立したノイズは互いに打ち消されるためです。10個の独立したシグナルの総ノイズは1つのシグナルの 10 倍ではなく、約 3.16 倍です(√10 ≈ 3.16)。
したがって、情報率 = 総収益 / 総リスク = (IC x N) / (σ x √N) = IC x (N / √N) = IC x √N となります。
これが IR = IC x √N の由来です。
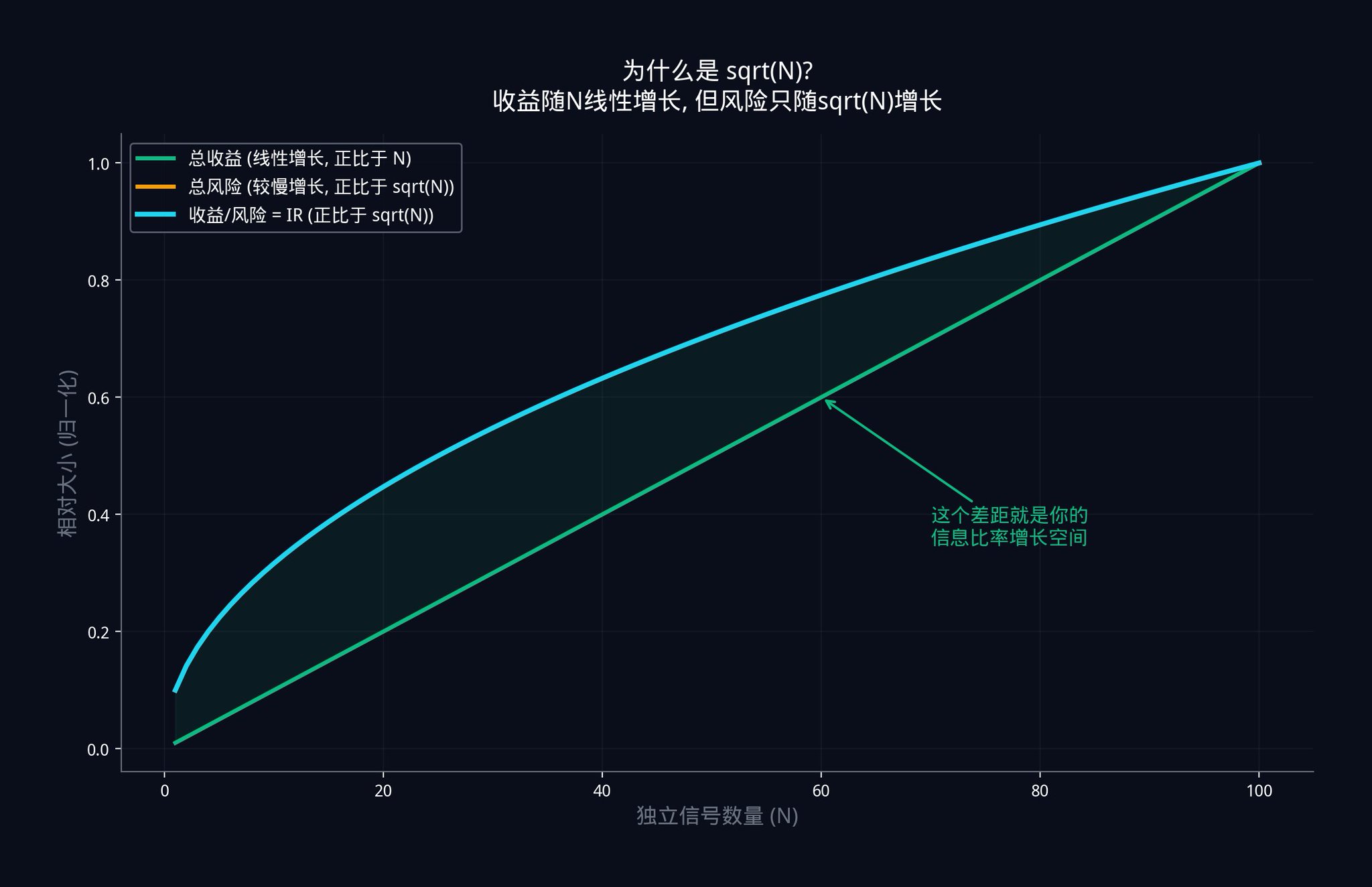
この関係を示す図が以下に示されています。緑色の線が総収益であり、シグナルの数に比例して線形に増加します。青色の線は情報率 IR であり、√N に比例して増加します。収益は増加していますが、リスクも増加しており、ただし収益がリスクよりも速く増加しています。2本の線の間の差がますます大きくなります。この差は、独立したシグナルを追加することで得られる取引上の利点です。
具体的な例を挙げて、この公式の力を実感してみましょう。
· シナリオ A:あなたは 50 個の弱いシグナルを持っています。各シグナルは非常に弱く、IC はわずか 0.05 です。したがって、あなたの組み合わせシステムの IR = 0.05 x √50 = 0.05 x 7.07 = 0.354 となります。
· シナリオ B:別のトレーダーは 1 つの強力なシグナルを持っています。彼は苦労して探し、非常に強力な単一のシグナルを見つけましたが、IC は 0.10 まで高く(あなたの2倍の正確さ)。ただし、彼は 1 つのシグナルしか持っていないため、彼の IR = 0.10 x √1 = 0.10 です。
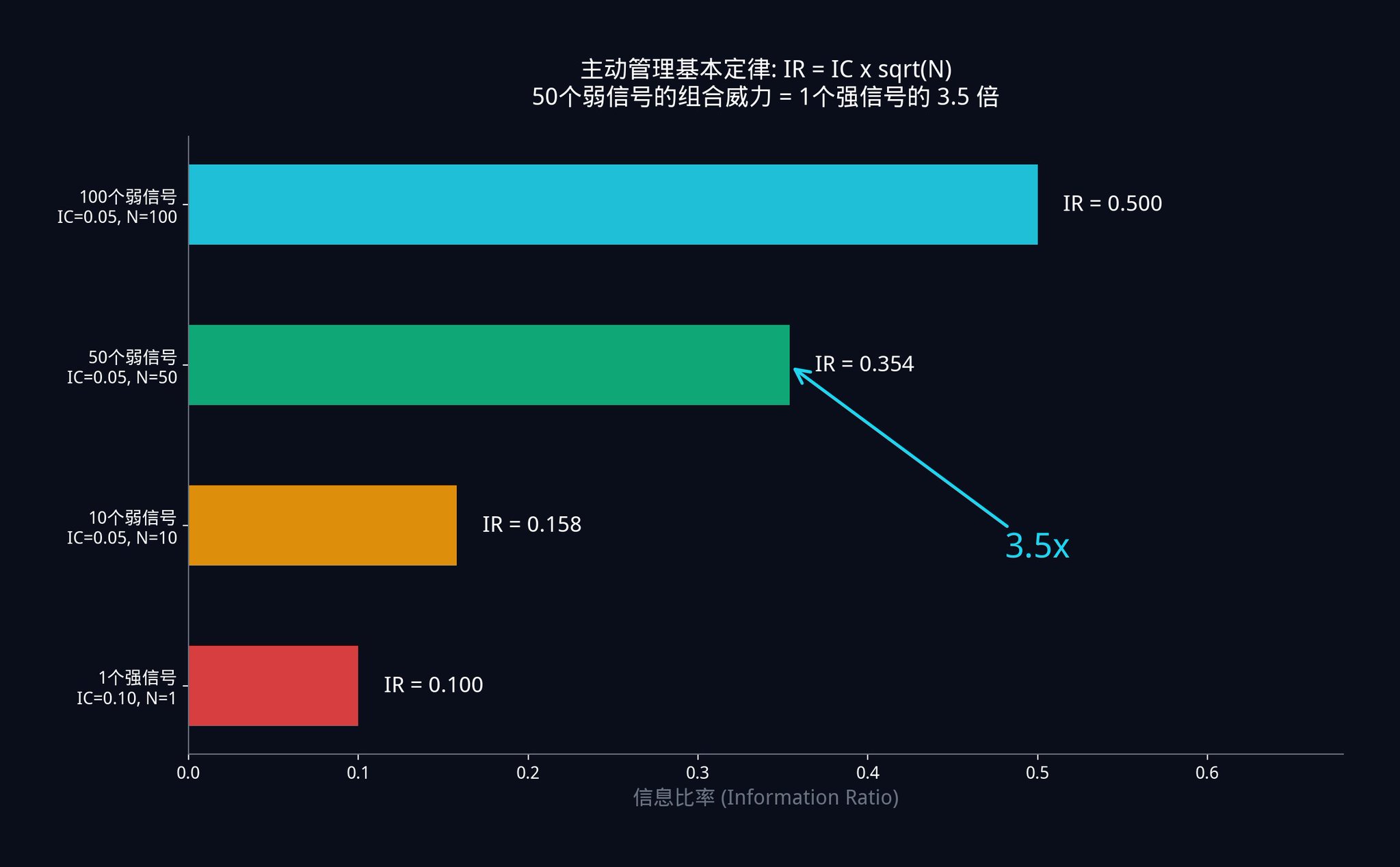
あなたは彼の半分の正確さしかない 50 個の「ジャンクシグナル」を使用して組み合わせたシステムのパフォーマンスは、彼の「神シグナル」の 3.5 倍です。
これがヘッジファンドが多くの研究者を雇い、多くの微弱なシグナルを探求することを選択し、すべてを「完璧な指標」に賭けることは絶対にしない理由です。数学は完璧なシグナルを探すことが行き詰まりだと証明しています。
正しいアプローチは次のとおりです:できるだけ多くの独立した弱いシグナルを収集し、それらを数学的に組み合わせることです。
このアイデアは、実際、insiders.bot ウォレットフィルターを開発する際の中心的なインスピレーションでもあります。ユーザーに「完璧なスマートマネーウォレット」を見つけさせるのではなく、数百もの異なる戦略を同時に追跡し、方向性や勝率の異なるウォレットを見ることで、これらの弱いシグナルを重ね合わせることで、本当に正確な結論を導くことができます
発展課題1:
現在最も信頼している取引シグナルを正直に評価してください。その情報係数(IC)はどれくらいですか?これをシステム的に評価したことがない場合、あなたは常に盲目的に行動していることを意味します。
Pythonを使って、過去30日間の予測ランキングと実際の結果ランキングを記録し、次に scipy.stats.spearmanr() 関数を使用してICを計算する単純なバックテストスクリプトを作成してみてください。その結果には驚かれるかもしれません。
確率論の基礎を固めたい場合は、ハーバード大学の無料の「確率論入門」をお勧めします。最初の6章で十分です。
信号を組み合わせる理由を理解したら、次のステップは次のようになります:これらの信号をどこで見つけるかを理解することです。
Part 2: Five Signal Raw Materials
第1部で、信号が何であるか(量的化可能で、方向性があり、繰り返し可能なデータポイント)を定義しました。
しかし、信号は非常に強力である必要はありません。それが必要なのは、たくさんの観測の中で、コイントスよりもわずかに正確であり、そしてこの「わずかに正確である」という特性が安定して検証可能であることです。
では、機関はどこでこれらの「わずかに正確な」データポイントを見つけるのでしょうか?
以下は、システマティックトレーディングデスクが実際に使用している5つの主要な信号のカテゴリーです。

2.1 Price and Momentum Signal
モメンタムシグナルは、過去の一定期間内に価格がどのように動いたか、その速度を見ます。
なぜモメンタムシグナルが効果的なのでしょうか?新しい情報に対する市場参加者の反応が慣性を持っているためです。
・短期間では、みんなの反応が遅れているため、トレンドが継続します。
· モーメンタムシグナル, 人々は再び過剰反応しやすく、それが価格の調整を引き起こす。
加速している列車を想像してみてください。運転手がスロットルを戻したとしても、列車はすぐに停止しません。慣性のため、それはまだ前進します。モーメンタムシグナルはこの「慣性距離」を捉えています。
Polymarket での使用方法は?
ある契約の価格が過去3日間に$0.40から着実に$0.55に上昇し、取引量も同時に拡大しているとします。これにより、持続的な買い圧が価格を推進していることが示されます。
価格が短期間に継続して上昇する可能性が高いです。これは内部情報を知っているからではなく、市場の慣性がまだ消費されていないからです。
量的研究では、最も基本的なモーメンタム式は過去d日の平均リターンを計算することです:E(i) = (1/d) x Σ R(i,s)。ここで、dは遡及日数、R(i,s)は契約iのs日目のリターンです。
2.2 ミーンリバージョンシグナル
ミーンリバージョンシグナルは、資産が「適正価値」からどれだけ離れているかを測定します。
その核心的な論理は、関連する資産間では、価格比率が安定しているはずだということです。この関係が壊れると、回帰の力がそれを引き戻します。
Polymarketの例を挙げましょう。2つの契約があるとします。「トランプ氏が選挙に勝つ」と「共和党が選挙に勝つ」。通常、これら2つの確率は高度に関連している必要があります(トランプ氏は共和党の候補者です)。ある日、「トランプ氏が勝つ」確率が10パーセント急落しましたが、「共和党が勝つ」確率はわずか2パーセント下落した場合、これは強力なミーンリバージョンシグナルです。市場の価格設定が間違っていますので、これらはいずれ再び整列します。
ミーンリバージョンシグナルはまるでゴムバンドのようです。あなたがそれを引っ張るほど、それが弾んで戻る力が強くなります。ただし、ゴムバンドは切れることもあります。そのため、ミーンリバージョンシグナルは単独ではなく、他のシグナルと組み合わせて使用する必要があります。
2.3 ボラティリティシグナル
ボラティリティシグナルは、暗黙のボラティリティ(市場の予想される変動幅)と実現されたボラティリティ(実際に発生した変動幅)の間の差を見ます。
なぜこの差が生じるのか?それは、波動率を売る者(たとえば、オプションを売る者)が大きなテールリスクを負っているからです。 彼らはその極端な事態をカバーするために追加の補償が必要です。 これは、保険会社が常に予想リスク以上の保険料を徴収するのと同じです。
Polymarketでは、波動率シグナルは次のように理解できます:合約の価格が0.45ドルから0.55ドルの間で急激に変動しても、基礎となる状況に実質的な変化がない場合(新しいニュースもなければ政策の変更もない)、そのような「偽の波動」自体がシグナルです。 これは、市場参加者がパニック状態にあるか興奮していることを示していますが、そのような感情はしばしば過剰であり、価格は最終的には適正水準に戻るでしょう。
2.4 ファクターシグナル
ファクターシグナルとは、数十年にわたる学術研究で確認された、体系的なリターン・プレミアムです。 最も有名な5つのファクターは次のとおりです:
· バリュー(Value)
· モメンタム(Momentum)
· 低ボラティリティ(Low Volatility)
· キャリー(Carry)
· クオリティ(Quality)
それぞれのファクターは、市場がリスクを価格設定する際の、人間の行動や市場構造の持続的な欠陥を表しています。
たとえば、「バリューファクター」が効果的であるのは、人間が人気のあるものを追い求めることが天性であるためです。 誰もが議論している契約は、しばしば十分に価格設定されています。 一方で、誰もが注目しない「マイナーな契約」には価格設定のずれがより存在しやすいです。
Polymarketでは、これは取引量が少なく、しかし基礎に変化がある契約を研究するのに時間を費やすべきであり、数千人が注目する人気の市場に追随するのではなく、そのような潜在的なアルファを持つ市場を見つけるために、insiders.botのホームページには波動率、最新マーケット、取引量、トレーダー数などの指標が追加されています。
2.5 ミクロ構造シグナル
ミクロ構造シグナルは、ハイ・フリクエンシー・トレーダーのお気に入りです。 これは、オーダーブックの深さの不均衡、売買スプレッドの動的変化、および攻撃的な取引量を見ています。
これらのシグナルの有効期間は非常に短く、通常数分から数時間です。しかし、これらは非常に重要なことを教えてくれます:実際の価格が動く前に、情報優位を持つ賢いお金がどこでポジションを取っているか。
マイクロストラクチャを測定する際に最もよく使用される指標の1つは、有効スプレッド(Effective Spread)です:
有効スプレッド = 2 x |取引価格 - ミドル価格|
有効スプレッドが大きいほど、市場の流動性が悪く、取引コストが高くなります。有効スプレッドが突然拡大すると、通常、インサイダー取引者が市場に参入しており、市場メーカーは自己保護のためにスプレッドを広げています。
もう1つの重要な指標は VPIN(Volume-Synchronized Probability of Informed Trading、取引量同期情報取引確率)です。この指標は、Easley、Lopez de Prado、O'Haraの3人の教授が2012年に提案しました。これは売買の取引量の不均衡を分析することで、市場で「知情取引者」によってどれだけの取引が駆動されているかを推定します。
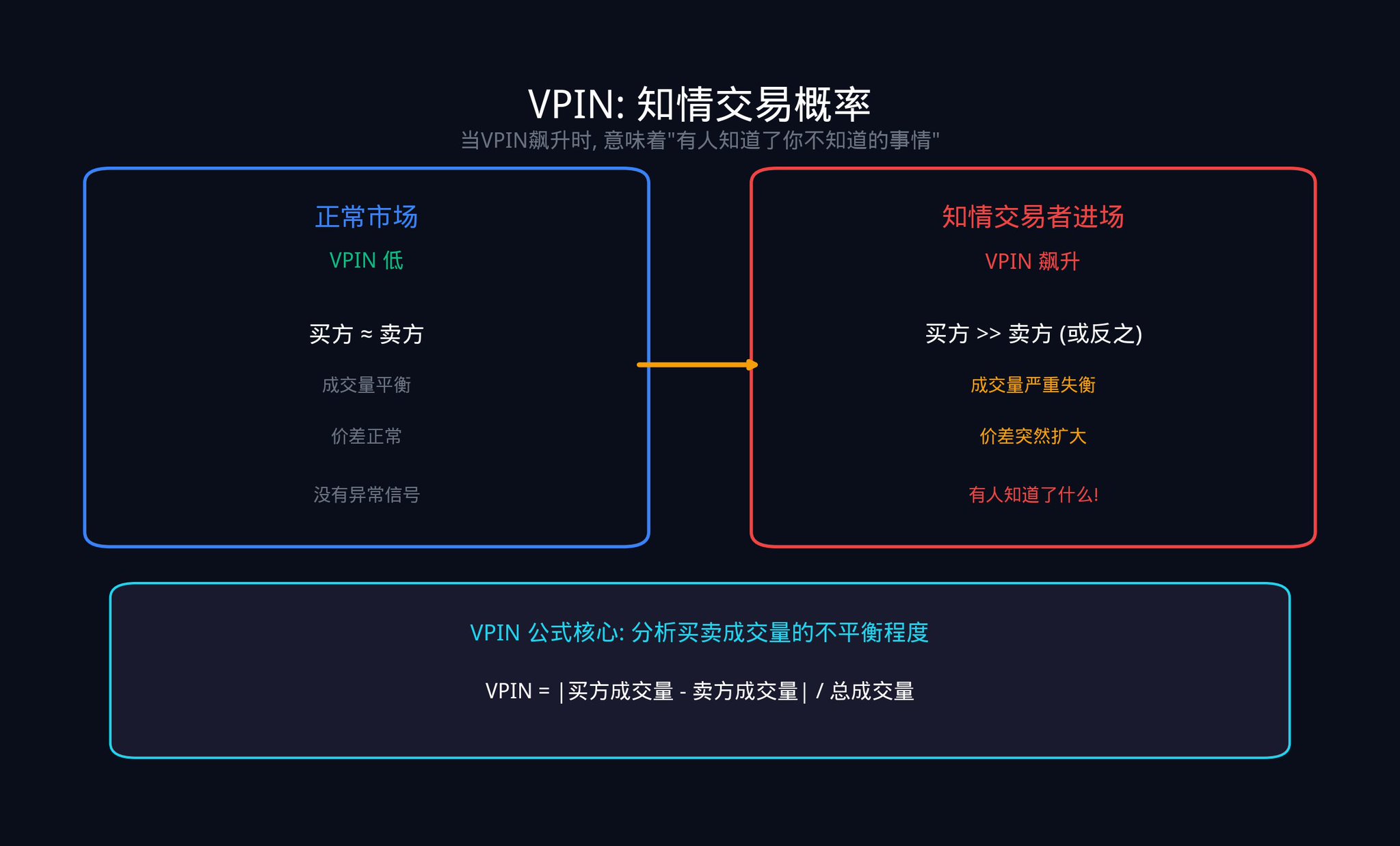
VPINの計算ロジックは非常に直感的です。取引量を固定サイズの「バケツ」(例:1000取引ごと)に分割し、各バケツ内の買い手取引量と売り手取引量の差を確認します。差が大きいと、一方が猛烈に攻撃していることを示し、通常は知情取引者が活動していることを意味します。
VPINが急上昇すると、誰かがあなたの知らないことを知っていることを示すことがよくあります。2010年の「フラッシュクラッシュ」(Flash Crash)の数時間前には、VPINが異常に急上昇していました。
Polymarketでは、賢いお金のチェーン上の行動が最も直接的なマイクロストラクチャシグナルです。勝率が65%を超える履歴を持つウォレットが突然特定の契約で大口の注文を入れると、これは非常に価値のあるシグナルです。
私たちがinsiders.botの賢いお金ブラウザーとv1.2/v1.3シグナルで行っていることは、基本的にこのようなチェーン上のマイクロストラクチャシグナルをリアルタイムであなたに提供することです。
覚えておいてください、これら5つのタイプのいずれか1つだけを取り出しても、体系的な優位性を形成するには不十分です。これらはすべて原材料にすぎません。
次に、最も重要な第三部分に入ります:原料を金に変える「組合エンジン」。
第三部分:11 ステップの組合エンジン
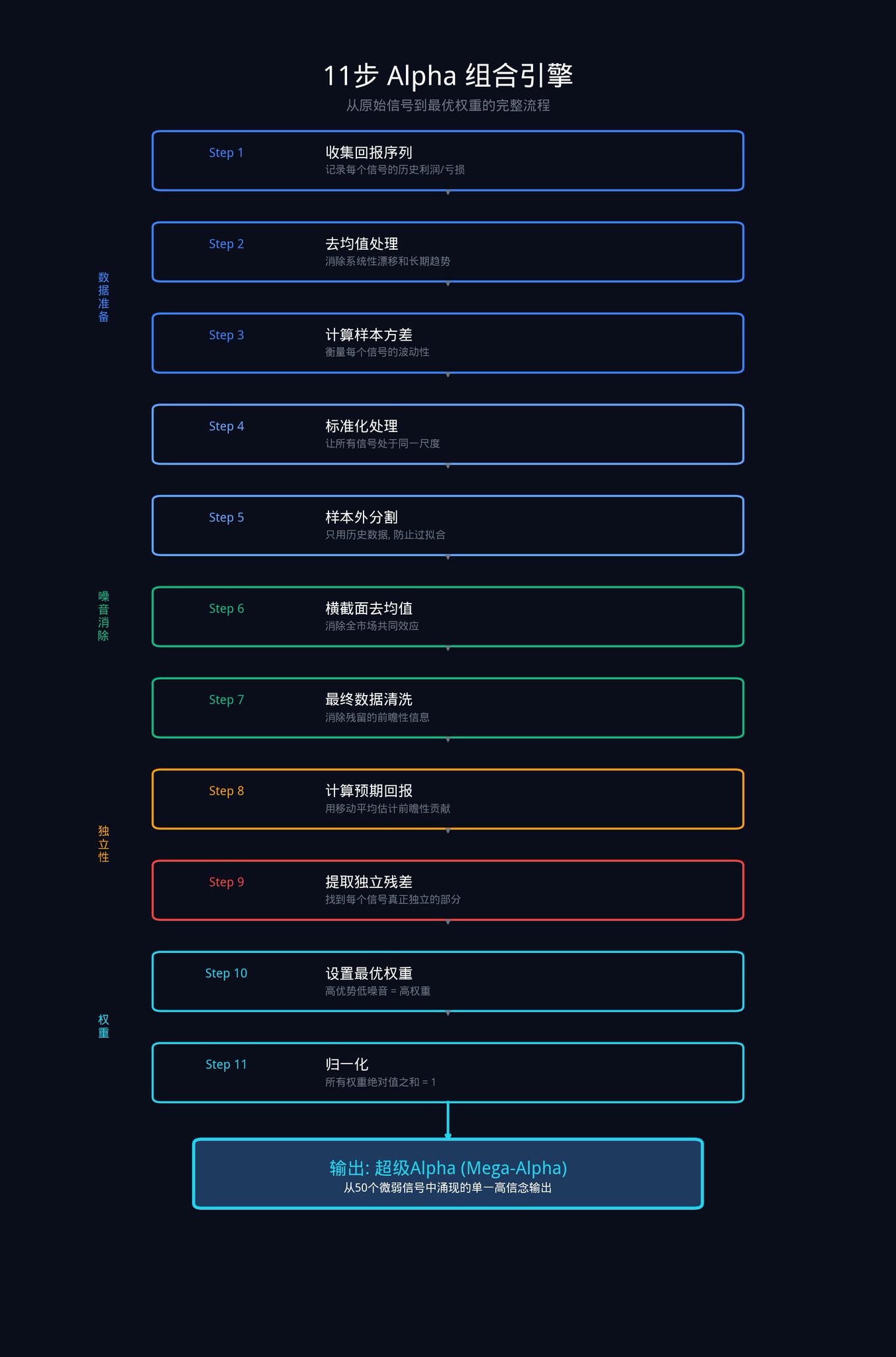
これは記事全体で最も重要な部分です。これらの11つのステップは、機関が一連の元のシグナルを最適な重み付けの組み合わせに変換するために使用する完全なプロセスです。
これらの11のステップは、次の4つの段階に分解できます:データの準備、市場ノイズの取り除き、独自の利点の抽出、最適な重みの割り当て。
まず大まかな背景について再説明します: N個のシグナル(たとえば50個)があると仮定します。各シグナルは過去の一定期間内に一連のリターンデータ(つまり、毎日いくら儲かったり損失したりしたか)を生成しました。
この組合システムが行うことは、これらの履歴データに基づいて、各シグナルにいくらの資金ウェイトを割り当てるかを計算することです。
段階1:データの準備
この段階の目標は、すべてのシグナルを同じスタートラインに立たせることです。
ステップ1:各シグナルの履歴パフォーマンスを収集する
これは最も基本的なステップです。各シグナルの過去の各時間帯の実際の利益または損失を記録する必要があります。
たとえば、モメンタムシグナルは過去30日間で、1日目に2%を稼ぎ、2日目に1%を失い、3日目に0.5%を稼いだ......。これらのデータをすべて記録します。各シグナルにはこのような列があります。
数学的に言えば、各シグナルiの各時間帯sでのリターンR(i,s)を収集します。
ステップ2:システムドリフトの除去(平均の削除)
各シグナルの過去のリターンから、そのシグナルの平均リターンを引きます。
なぜこれを行うのですか?
例を挙げます。
· ある「ダイブイン買い」シグナルがあるとします。過去1年間、全体的に暗号市場は急騰していたため、このシグナルは多くの利益を上げたように見えます。
· しかし、本当にこのシグナルのおかげなのでしょうか? 必ずしもそうではありません。牛市ではどんなストラテジーでもお金を稼げるかもしれません。平均値を引いた後、このシグナルが実際に予測能力を持っているかどうかを、「市場全体のトレンドが除外された」状態で確認できます。
具体的な式:X(i,s) = R(i,s) - 平均値(R(i))。
ステップ 3:各シグナルのボラティリティを計算する
このステップでは、各シグナルのリターンのボラティリティを測定します。
・ 1つのシグナルは平均して毎日 0.1%を稼ぎますが、時々 5%を稼ぎ、時々 4%を失います。
・ もう1つのシグナルも平均して毎日 0.1%を稼ぎますが、波動範囲は -0.5% から +0.7% の間にしかありません。
・ 2つのシグナルの平均リターンは同じですが、2番目のシグナルの方が明らかに「安定している」ため、信頼できると言えます。
ボラティリティはこのような「安定度」を定量化するために使用されます。
具体的な式:σ(i)² = (1/M) x Σ X(i,s)²。
ステップ 4:標準化処理
ステップ2の結果をステップ3のボラティリティで割ります。
なぜこのステップが必要なのでしょうか? 異なるシグナルは異なる「単位」で表されます。モメンタムシグナルはパーセンテージで計算される場合があり、マイクロストラクチャーシグナルはベーシスポイント(0.01%)で計算される場合があり、ボラティリティシグナルは絶対数値で計算される場合があります。これらを直接比較すると、りんごとオレンジを比較しているようなもので、まったく意味がありません。
標準化することで、すべてのシグナルが同じ尺度に落とされます。ドル、ユーロ、円をすべて同じ通貨に換算するように、これにより公平に比較することができます。
具体的な式:Y(i,s) = X(i,s) / σ(i)。
段階2:マーケットノイズの排除
この段階の目標は、各シグナルのパフォーマンスから「市場全体の上昇と下落」を取り除き、シグナル自体の真の能力のみを残すことです。
ステップ5:アウトオブサンプル分割
ウェイトを計算する際には、過去のデータのみを使用し、最新の観測値を破棄します。
このステップは「過剰適合」を防ぐために行われます。
過剰適合とは何でしょう?たとえば、ある学生が過去10年間の試験問題をすべて丸暗記し、模擬試験ではいつも満点を取ります。しかし、本番の試験になると、新しい問題になり、全然解けなくなります。彼は「知識を理解している」のではなく、「答えを暗記している」のです。
量的取引では、過剰適合はより深刻なリスクです。あなたのモデルは過去のデータで完璧なパフォーマンスを示すかもしれませんが、実際の取引ではうまくいかないかもしれません。アウトオブサンプル分割は、あなたのモデルが「パターンを学んでいる」ことを確認するためのものであり、「過去を記憶している」のではありません。
具体的な手法は以下の通りです。
データを2つの部分に分割します。
· モデルをトレーニングするためにデータの前80%を使用します(ウェイトの計算)、
· モデルが本当に効果的かどうかを検証するためにデータの残り20%を使用します。
· モデルが残りの20%のデータでも利益を上げる場合、それは本当のパターンを学んでいることを示しています。
ステップ6:横断面の平均除去(Cross-sectional Demeaning)
各時間点で、各シグナルのパフォーマンスからその時間点でのすべてのシグナルの平均パフォーマンスを引きます。
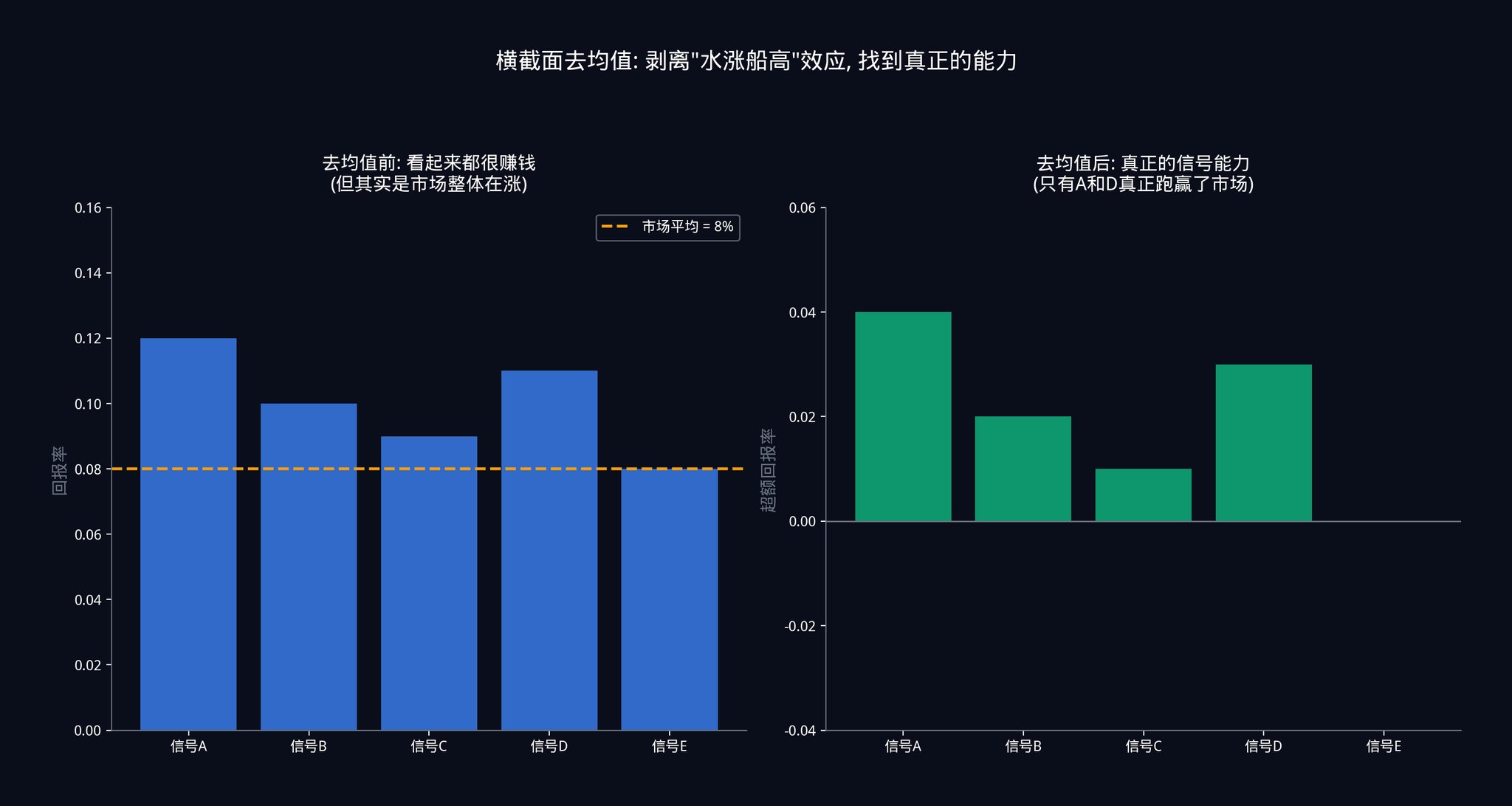
このステップは非常に重要です。ここでは具体的なシナリオで説明します。
例えば、今日、米連邦準備制度が突然利下げを発表しました。市場全体が急上昇しました。あなたの50のシグナルはすべて同時に「買い」の指示を出したかもしれず、そしてどのシグナルも利益を上げたように見えるかもしれません。
横断面の平均除去をしなければ、あなたはこれら50のシグナル全てが非常に正確であると思うでしょう。しかし実際は、これは「水位が高くなる」効果だけです。市場全体が上昇しており、あなたのシグナルは予測に関係なく利益を上げるでしょう。これはシグナルの能力ではなく、市場からの恩恵です。
全てのシグナルから平均パフォーマンスを差し引いた後、あなたは真実を見ることができます:皆がお金を稼いでいる日に、どのシグナルが他の人よりも多くを稼いでいたのか?皆が損失している日に、どのシグナルが他の人よりも少なく損失していたのか?この「相対的なパフォーマンス」こそがシグナルの真の能力です。
より具体的に言うと: Λ(i,s) = Y(i,s) - (1/N) x Σ Y(j,s)。
*注意:ステップ2の「メンディアン除去」およびステップ6の「横断面メンディアン除去」は異なります。ステップ2は各シグナルの時間系列ごとのメンディアン除去(長期トレンドの除去)です。ステップ6は各時間点で、すべてのシグナル間のメンディアン除去(市場全体の影響の除去)です。どちらも欠かせません。
ステップ7:最終的なデータクリーニング
これは最終的なデータクリーニングの段階です。これにより、データ系列に未来の「先見的情報」が残っていないことが確認されます。
先見的情報とは何でしょうか?それは、意思決定を行う時点で将来のデータを知ることができない情報のことです。たとえば、月曜日に金曜日の終値を使って決定を下すことはできません。これはあたりまえのことのように聞こえますが、複雑なデータ処理フローでは、この種の「データリーク」は想像以上に起こりやすいです。
フェーズ3:独立したアドバンテージの抽出
この段階はエンジン全体の魂です。それが行うことは、それぞれのシグナルから、その独自の予測能力を引き出し、他のシグナルとの重複部分を取り除くことです。
ステップ8:期待リターンの計算
移動平均線を使用して、各シグナルの将来の期待される寄与度を計算します。
具体的には、各シグナルの直近d日間の平均リターンを、その将来のパフォーマンス予測として使用します。そしてこの予測値を標準化します(ボラティリティで割り、異なるシグナルの期待リターンを直接比較できるようにします)。
数式で表すと:
· E(i) = (1/d) x Σ R(i,s)
· E_norm(i) = E(i) / σ(i)。
ステップ9:独立した残差の抽出(Orthogonalization,正交化)
これは全体の 11 ステップの中で最も重要なステップです。
2 つのシグナルを持っていると仮定します。
・ シグナル A は「天気予報を見る」
・ シグナル B は「通行人が傘を持っているかを見る」。
これら 2 つのシグナルは、今日の雨の可能性を予測できます。
しかし問題は、通行人が傘を持っているのはおそらく天気予報を見たからです。したがって、シグナル A とシグナル B の間には多くの情報が重なっています。それらを同時に使用すると、2 つの独立したシグナルを持っていると思うかもしれませんが、実際には 1 つのシグナル(天気予報)が 2 回表現されているだけです。
第 9 ステップの目的は、このような情報の重なりを取り除くことです。
具体的にはどのように行うのでしょうか?各シグナルの正規化された期待リターン E_norm(i) について、他のすべてのシグナルの過去データ Λ(i,s) を使用して回帰分析を行います。回帰とは、他のシグナルがこのシグナルを「説明」するために使用されることを意味します。説明可能な部分は重なりの部分ですが、それを削除します。説明できない部分は、このシグナルの固有の貢献であり、保持されます。
この「説明できない部分」は、数学的には残差(Residual)と呼ばれ、ε(i) と表記されます。
線形代数を学んだことがある場合、これは Gram-Schmidt の直交化の応用です。学んだことがない場合でも問題ありません。覚えておくべきことは 1 つだけです:第 9 ステップは、各シグナルの本当に固有でかつ代替不可能な予測能力を特定することです。
段階 4:最適な重み付けの割り当て
第 10 ステップ:最適な重みの設定
重みの計算式は:w(i) = η x ε(i) / σ(i)。
この式は次のように述べています:各シグナルの重みは、その固有の貢献 ε(i)(第 9 ステップで算出された)をその波動率 σ(i)(第 3 ステップで算出された)で割ったものにスケーリング係数 η を乗じたものです。
これは何を意味していますか?エンジンは自動的に、「大きな固有貢献を持ち」「安定したパフォーマンスを示す」シグナルにより高い重みを割り当てます。一方で、「ノイズが多い」または「他の信号に追随するだけの」シグナルは自動的に重要度が低くなります。
すべては数学的に自動化されており、どんな主観的判断も必要ありません。あなたは「このシグナルがどれだけの割合を占めるべきか」を感覚に頼る必要がありません。式が最適な答えを教えてくれます。
ステップ 11:正規化
最後のステップで、スケーリング係数 η を調整し、すべての重みの絶対値の合計が 1 になるようにします。
これにより、総資金割り当てが 100% になり、無意識のうちにレバレッジが追加されることはありません。このステップを踏まないと、重みの合計が 150% になる可能性があり、つまり、1.5 倍のレバレッジ取引を行っていることになりますが、自覚が全くありません。
数学的に言えば、Σ|w(i)| = 1 となるように η を設定します。
これら 11 のステップの最終的な出力は、N 個のシグナルのそれぞれに対する最適な重みです。これらの微弱なシグナルを重み付けして組み合わせると、スーパーアルファ(メガアルファ)が得られます。高い勝率と高い信念を持つ単一の出力です。
Advanced Exercise 2:
このプログラムを現在のシグナルスタックに実行した場合、どのシグナルが高い重みを持ち、どのシグナルが低い重みを持つかに驚くでしょうか?答えは、実行中のものに対する自己の独立構造の理解度を示します。
この行列演算の背後にあるロジックをより深く理解したい場合は、MIT の無料オンライン講座 Linear Algebra の直交化に関するセクションを見ることを強くお勧めします。Gilbert Strang 教授の説明は非常に明確です。
Part 4: Independence Trap
組合せエンジンは1つの問題を解決します。この問題は、1度に1つのシグナルを見るときには見えませんが、数学を理解するとどこにでも存在します。
最初の部分で触れたアクティブマネジメントの基本法則に戻りましょう:
IR = IC x √N
これらの3つの文字が何を表しているか覚えていますか?IR はあなたのシステム全体の「リスク調整後のリターン」(つまり、あなたの戦略の安定性)。IC はあなたの単一のシグナルの平均精度です。N はあなたのポートフォリオの独立したシグナルの数です。
今、私が強調したいのは、多くの人が無視しているキーワードです:独立。
ここでの N は、あなたのシグナルスタック内のシグナルの総数ではありません。それは有効な独立したシグナルの数です。これら2つの数字の間には大きな違いがあるかもしれません。
なぜか? シグナルは「こっそりと」互いに関連しているからです。
モメンタムシグナルと平均回帰シグナルは、性質上完全に対照的に見えます(ワンはトレンドフォロー、もう一つはリバウンド)。しかし、ある市場環境では、これら2つのシグナルが同時に、同じ方向で、同じマクロ経済ニュースに反応することがあります。
· 例えば、連邦準備制度が突然利上げを行うと、モメンタムシグナルは「トレンドは下降、売り」と言い、平均回帰シグナルも「平均からの逸脱が大きすぎるが、方向も下降」と言います。
· この瞬間に、2つの独立したように見えるシグナルは、実際には同じ観点を表現しています。
それらに等しい重みを与えると、リスクを2つの独立した観点に分散していると思うかもしれませんが、実際にはあなたは単一の観点に2倍のポジションを乗せているのです。

これが第3部のステップ6(横断面平均除去、つまり各時間点ですべてのシグナルの平均パフォーマンスを差し引くことにより、「水増し」効果を排除する)およびステップ9(独立した残差の抽出、つまり回帰分析によってシグナル間の情報オーバーラップを取り除き、各シグナル固有の寄与だけを残す)が非常に重要な理由です。それらの役割は、シグナル間の隠れた共有成分を識別し除去することです。
50個の関連するシグナルを実行しても、おそらく10〜15個の独立したシグナルの分散化効果しか得られません。あなたのシグナルが本当に独立した情報源に基づいており、組み合わせエンジンが正しく機能している場合にのみ、50個のシグナルの全盛りの利点を得ることができます。
実際の取引でこれは何を意味するのでしょうか?
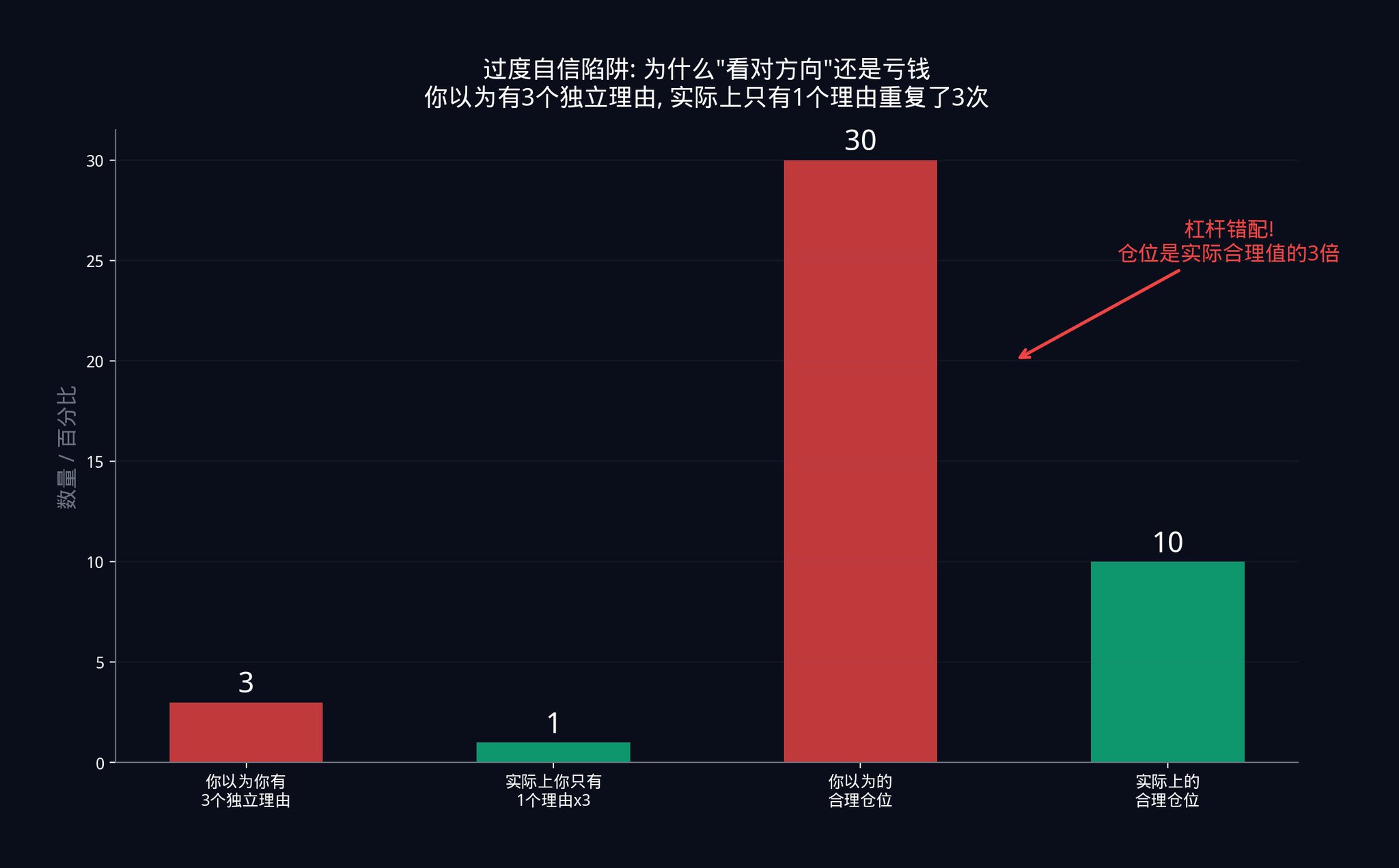
· 例えば、トレーダーが自分が20個の独立したシグナルを実行していると考えるとします。彼は20個の独立したシグナルに基づいてポジションサイズを計算します。しかし、実際には、シグナル間の隠れた相関関係のため、彼にはたった6つの有効な独立したシグナルしかありません。
· 20個の独立したシグナルに基づくポジションサイズは、6つのシグナルには大きすぎます。どれくらい大きいか? 20/6 ≈ 3.3 倍大きいです。彼の実際のレバレッジは、彼が考えていた3倍よりも実際には大きいです。
このようなレバレッジのミスマッチは、ほとんどのシステマティックストラテジーのロスカットの背後にある真の原因です。トレーダーは方向的には正しいですが、スケール的には誤っています。彼は市場が上昇すると正確に予測しましたが、賭け金が大きすぎました。通常の調整が行われるだけで清算される可能性があります。
ポートフォリオエンジンは正直な会計処理を強制します。それは自己欺瞞を許しません。それは、信号スタックの実際の独立性構造がどのようなものかを教えてくれます。そして、実際の状況に基づいて重み付けを行い、あなたが考えている状況に基づいていません。
分析上正しい取引で継続的に損失を被るトレーダーの多くは、測定していない相関に敗れます。彼らは3つの独立した理由を持って自信を持っていると思っています。実際には、彼らは1つの理由を3回表現しているだけです。そして、ポジションは3つの理由に基づいて取られます。
ポートフォリオエンジンは、このような失敗パターンを構造的に排除します。
高度な演習3:
現在使用中のすべての信号を取り出し、すべてのペアを作成し、それらの間の相関係数を計算します。Pythonの numpy.corrcoef() 関数を使用できます。いずれかの信号の相関係数が0.5を超える場合、数学的には独立していません。信号スタックを再評価する必要があります。
Marcos Lopez de Prado の Advances in Financial Machine Learning をお勧めします。特に特徴の重要性と直交化に関する章を読んでください。この本は現代の量的手法の必読書です。
Part 5: Landing on Polymarket
前述の4つのパートでは、株式とマルチアセットシステマティックトレードの背景に関するすべての内容が構築されています。良いニュースは、この数学セットを直接予測市場に移行できることです。ただし、1つの置き換えが必要です:あなたは「期待リターン」に関する組合せではなく、「期待確率」に関する組合せを行っています。
予測市場では、各信号が生成するのはリターンの推定ではなく、暗黙の確率の推定です。
5.1 5つの確率信号
最初、クロスプラットフォーム価格設定シグナル: もし、Polymarket 上のある契約の YES 価格が $0.45 であるが、Betfair 上で同じイベントのオッズが52%の確率を示している場合、この7ポイントの価格差はあなたの信号です。2つのプラットフォームが同じイベントに対して異なる価格を付けている場合、少なくとも1つは間違っています。
第二、キャリブレーション シグナル: Polymarket の 40 億件の歴史取引に関する研究では、5% から 15% の価格設定で合意された契約のうち、最終的に YES と解決された割合は 4% から 9% にすぎないという、体系的なバイアスが見つかりました。これは市場が低確率イベントの発生を体系的に過大評価していることを意味します。このバイアスは安定しており、繰り返し発生するため、有効なシグナルです。
第三、ベイズ更新 シグナル: これは量子取引の核心ツールです。このツールが答えるのは、新しいデータを入手した場合、どのようにして既存の信念を正確に更新すべきかという基本的な問いです。
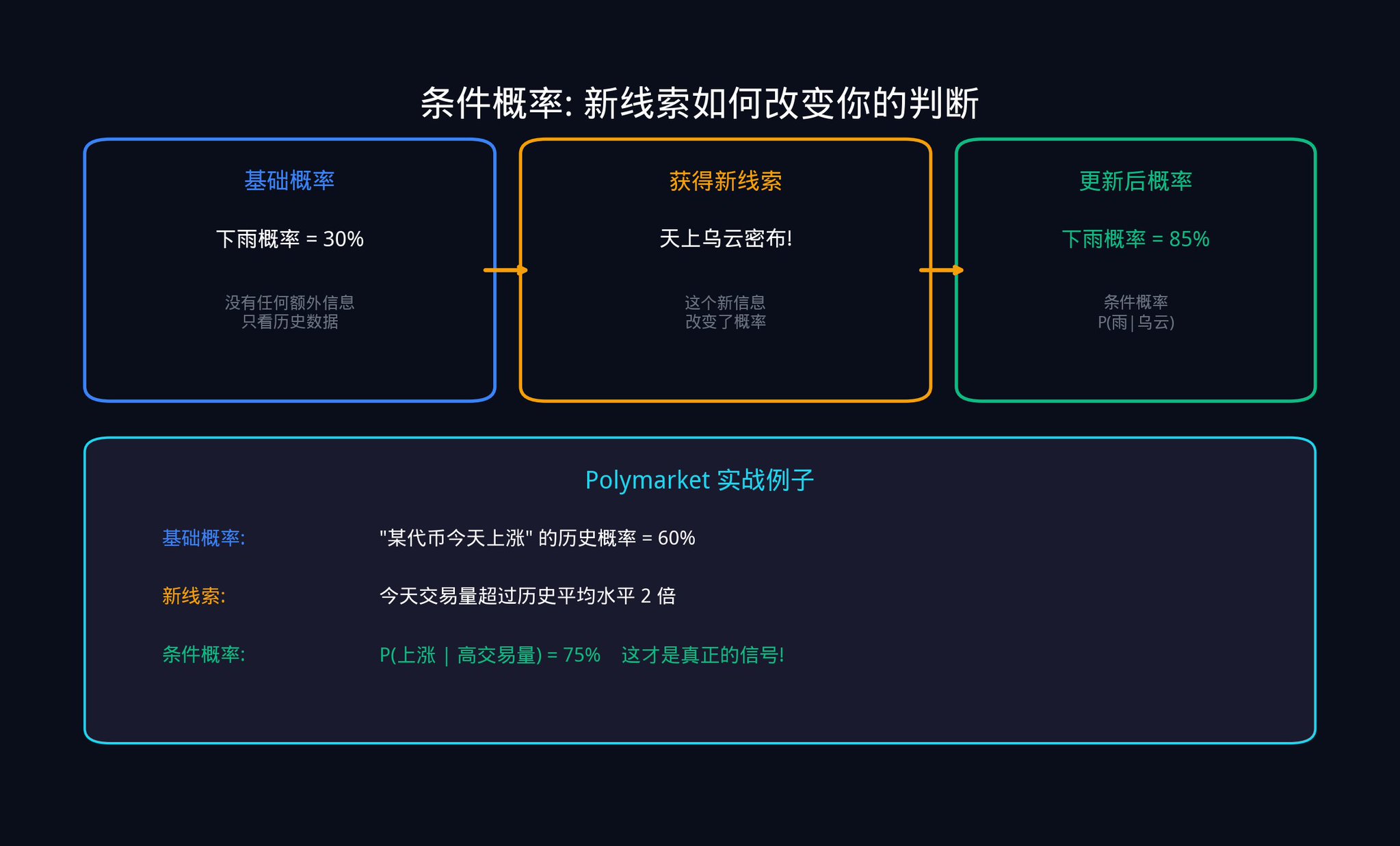
具体例を使ってベイズ更新を説明しましょう。
Polymarket の契約に注目しているとしましょう:「今月、ある法案が通過するか?」。現在の市場価格は 0.40 ドルで、つまり市場は通過確率を 40% と見積もっています。これがあなたの先行確率(Prior)です。
突然ですが、あるニュースが出ました:その法案が重要な上院議員から公然と支持されています。
確率を直ちに 80% に変更するわけにはいきません。正確な計算のためにはベイズの式を使用する必要があります。
ベイズの式:
P(通過|支持) = P(支持|通過) × P(通過) / P(支持)
平易な言葉で言うと:
「その上院議員が公然と支持している状況で、法案が通過する確率」=「法案が実際に通過するなら、その上院議員が公然と支持する確率」×「法案の先行確率」 / 「その上院議員が公然と支持する全体の確率」
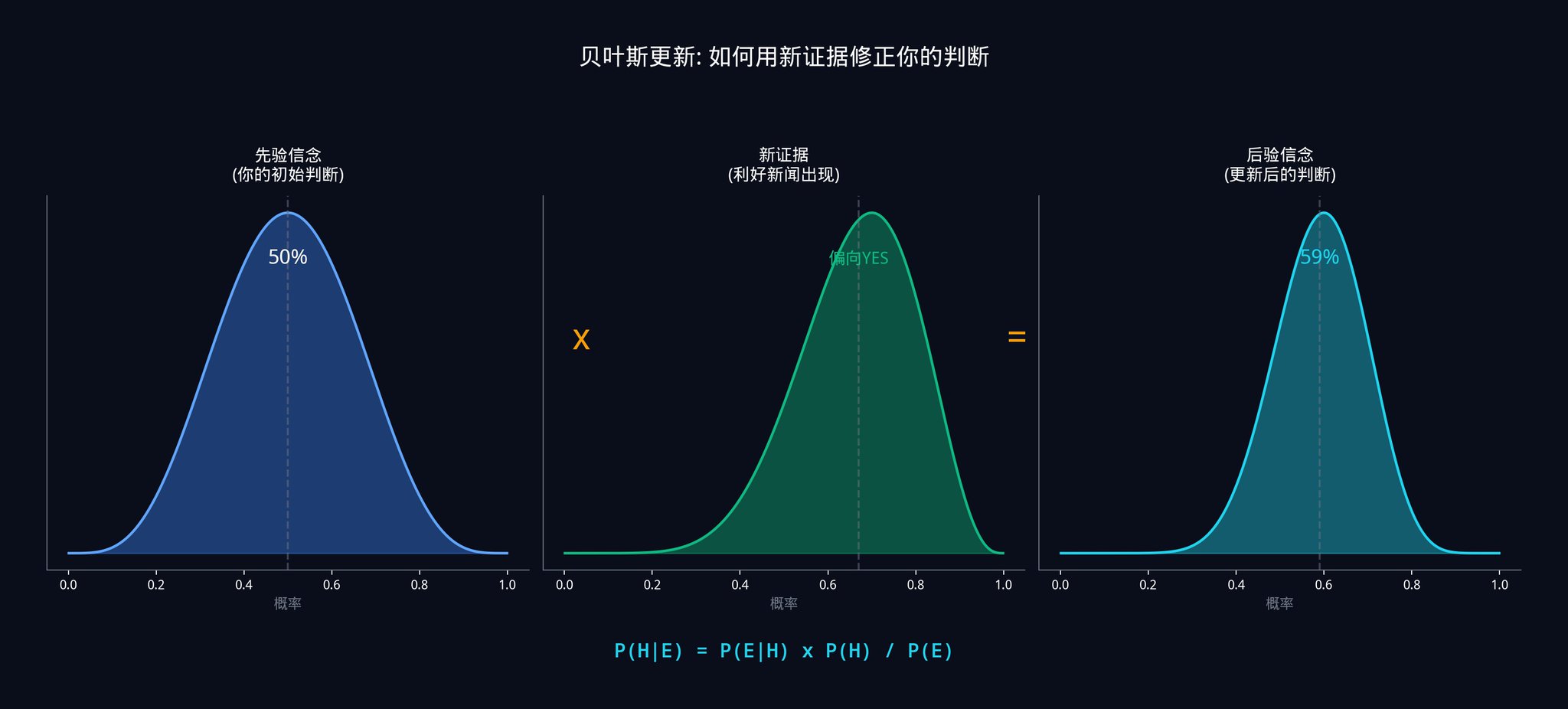
以下のように見積もるとします:
・ 法案が実際に通過する場合、その上院議員が公然と支持する確率は 80%(自信がある場合にのみ表明するため)
・ 法案が通過しない場合、その上院議員が公然と支持する確率は 20%(ときには間違った側に立つこともあるため)
・ 法案の先行確率は 40%
· P(サポート) = 0.80 x 0.40 + 0.20 x 0.60 = 0.32 + 0.12 = 0.44
· P(支持された場合の合格) = 0.80 x 0.40 / 0.44 = 0.32 / 0.44 = 72.7%
このニュースを見た後、法案が承認される確率を40%から72.7%に更新すべきです。市場価格がまだ0.50ドルである場合、22.7%のアドバンテージを得ます。
ベイズ更新の要点は、あなたが新しい確率を単なる「推測」しているのではなく、数学的に正確に計算していることです。あなたの判断には根拠があります。
第四、ミクロ構造シグナル: VPIN(第2部で説明した「インフォームド・トレード・プロバビリティ」指標を使用し、取引の不均衡を分析して、インサイダートレーダーの活動の有無を示唆します)および有効スプレッドを使用して、インサイダーオーダーフローの方向から確率を示唆します。
第五、モメンタムシグナル: 解決に近づいた契約の価格変動速度と方向に基づいて、確率を示唆します。
5.2 シグナルからベットへ:完全なプロセス
これらの暗黙の確率推定をすべて、第3部で説明した11段階のコンポーネントエンジンに従って実行します。出力は単一の加重合計確率推定です。この推定値は、各シグナルの独立した寄与に基づいて(第9ステップで説明された直交化を覚えていますか?情報の重複を排除し、ユニークな部分だけを保持することを意味します)数学的に最適な重みが割り当てられます。
その組み合わせ推定値と現在のPolymarket価格との間の差は、あなたのアドバンテージ(Edge)です。
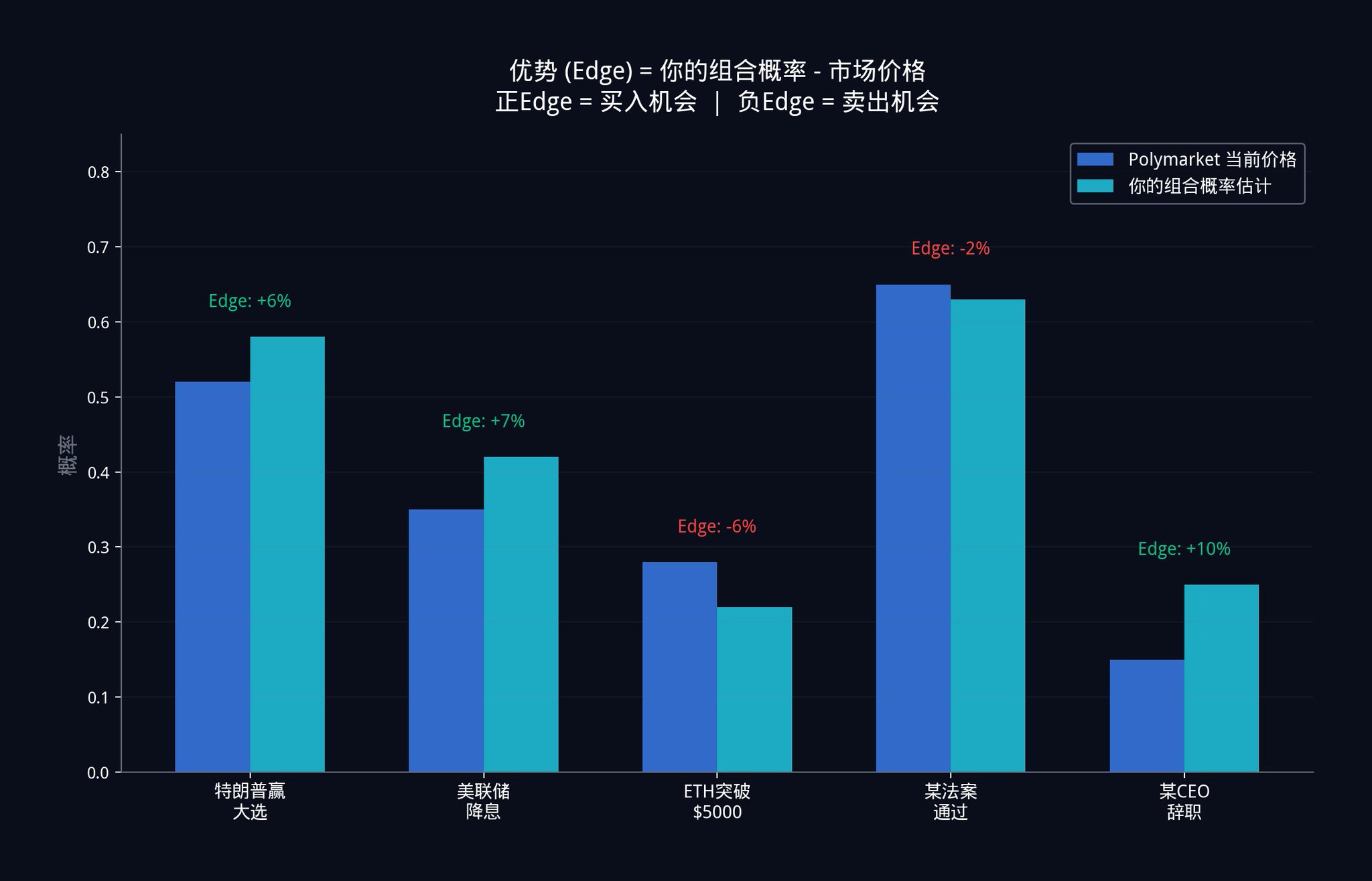
5.3 ケリーの公式:いくら賭けるべきか?
アドバンテージを得た後、最も重要な問題が発生します:いくら賭けるべきか?
賭けすぎると、アドバンテージを無駄にし、利益が少なくなります。賭けすぎると、1回の判断ミスで最初からやり直す可能性があります。
機関はケリーの公式(Kelly Criterion)を使用しています。標準的なケリーの公式は次のとおりです:
f_kelly = (p x b - q) / b
ここで、p はあなたの推定勝率(あなたのポートフォリオの確率)、q = 1 - p は敗率、b はオッズです。
Polymarketでは、オッズ b は直接価格から計算できます:b = (1 / マーケット価格) - 1。たとえば、マーケット価格が $0.40 の場合、b = (1/0.40) - 1 = 1.5 になります。
あなたのポートフォリオモデルが真の確率が60%(つまり、p = 0.60)であり、マーケット価格が $0.40(オッズ b = 1.5)であるとします。この場合、標準ケリー戦略に従って賭けるべき金額は次のとおりです:
f_kelly = (0.60 x 1.5 - 0.40) / 1.5 = (0.90 - 0.40) / 1.5 = 0.50 / 1.5 = 33.3% of your capital。
しかし、標準ケリー戦略には致命的な仮定があります:あなたの勝率推定が100%正確であると仮定しています。現実には、あなたの推定には常に誤差があります。したがって、機関は経験的ケリー戦略を使用しており、これには「不確実性ペナルティ」が組み込まれています。
f_empirical = f_kelly x (1 - CV_edge)
ここで、CV_edge はあなたの優位性推定の変動係数(Coefficient of Variation)です。これは、あなたの推定がどれだけ不確かかを示しています。CV_edge が大きいほど、不確かさが高く、式に従って賭け金が自動的に減少します。
CV_edge をどのように計算すればよいでしょうか?モンテカルロシミュレーションを使用することができます。要するに、モデルを数千回シミュレーションして、さまざまなシナリオであなたの優位性推定がどれだけ変化するかを確認します。変化が大きいほど、CV_edge が高くなり、賭け金を減らすべきです。
先ほどの例に戻ります。CV_edge = 0.3 の場合(つまり、あなたの推定が30%の不確かさがある場合)、経験的ケリー戦略に従って賭けるべき金額は次のとおりです:
f_empirical = 33.3% x (1 - 0.3) = 33.3% x 0.7 = 23.3% of your capital。
実際の運用では、多くの機関は「ハーフケリー」(Half-Kelly)のみを行うことさえあります。つまり、さらに2で割って約12%になります。なぜなら、長期的には、リスクを軽減することが重要だからです。
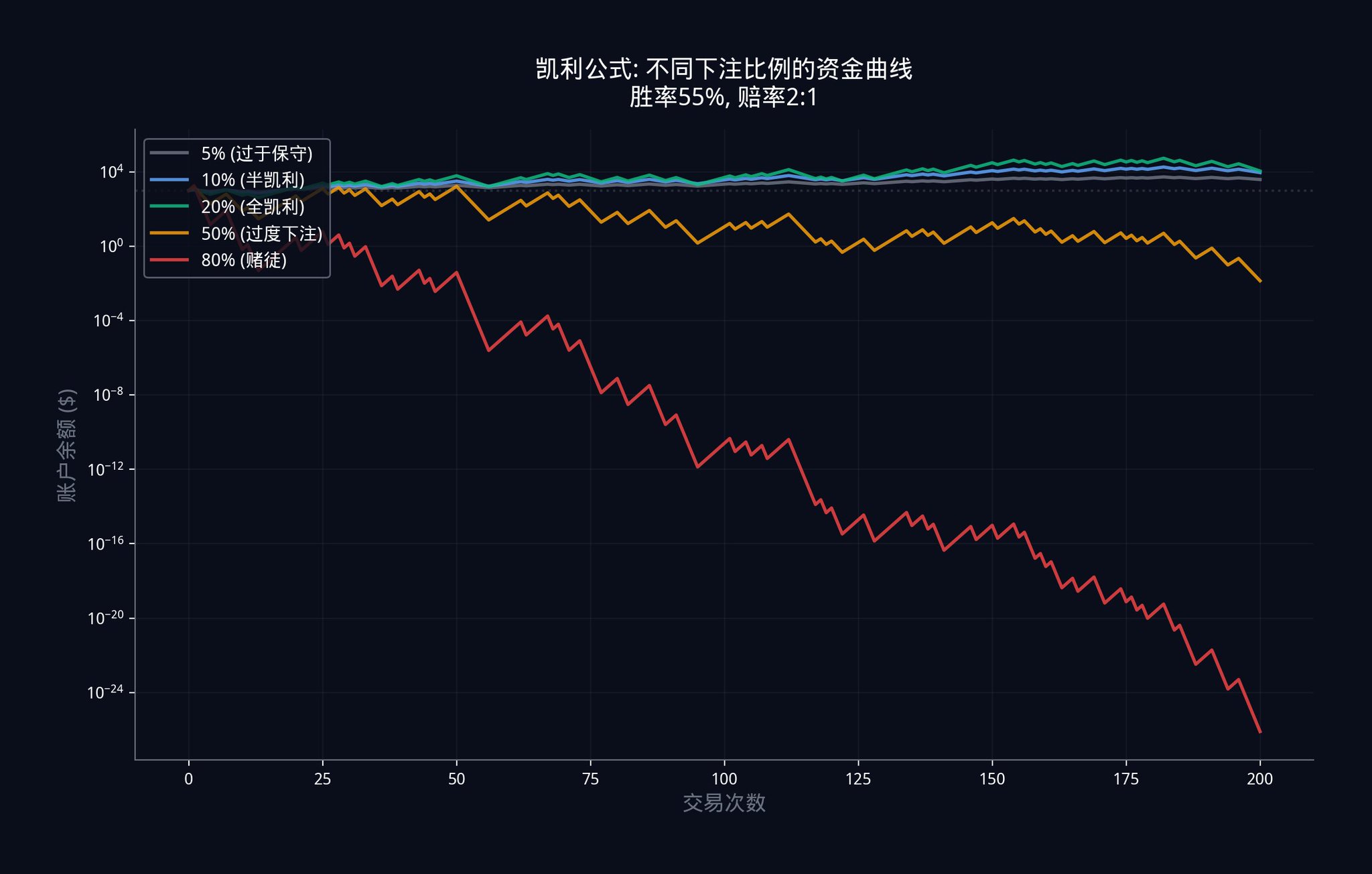
5.4 ポリマーケットの完全な取引パイプライン
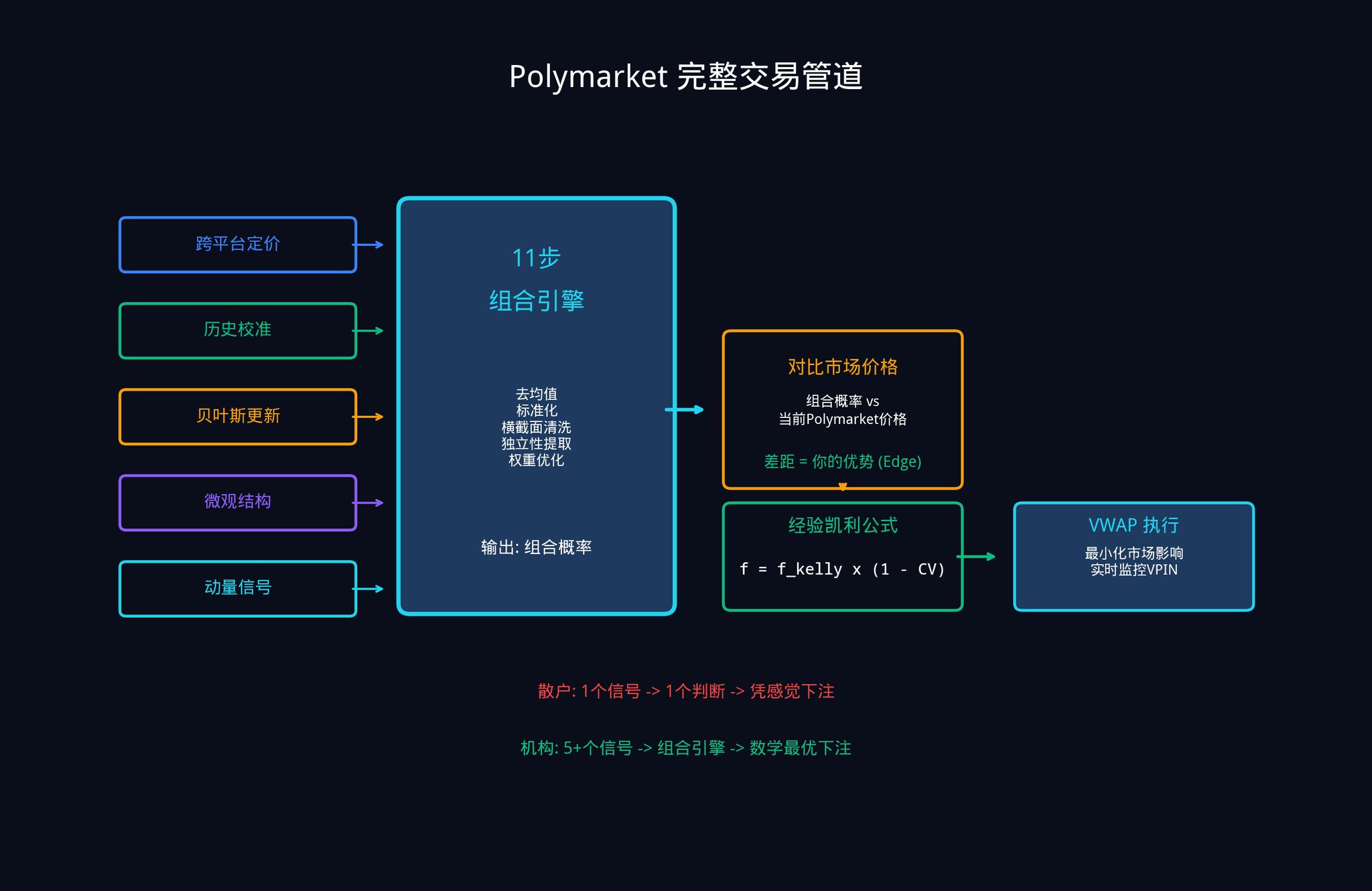
すべてをつなぎ合わせると、完全なワークフローは次のようになります:
1. 5つ以上の入力信号、それぞれが暗黙の確率推定を生成
2. 11段階の組み合わせエンジンを介して処理
3. 1つの加重された組み合わせ確率を出力
4. 現在の市場価格と比較して、あなたのエッジを計算
5. 経験則ケリーの式を使用してベットサイズを決定
6. VWAP(取引高加重平均価格)を使用して実行を最適化し、大口注文が市場価格に与える影響を減らす
7. VPIN変化をリアルタイムでモニタリングし、インサイダー取引業者が活発になると戦略を素早く調整
このフレームワークは、予測市場にとって特に価値があります。その理由は非常にシンプルです:あなたのほとんどの競争相手は、単一のモデル、単一のデータソース、単一の確率推定を使用して取引しています。一方、あなたはすでに複数の弱いシグナルを1つの強いシグナルに組み合わせる方法を知っています。これがあなたの構造的優位性です。
高度な演習4:
関心のあるポリマーケット契約を選択します。少なくとも3つの異なる視点(たとえば、クロスプラットフォーム価格設定、履歴の校正、最近のニュースイベントなど)からそれの確率をそれぞれ推定してください。その後、重み付け平均を取り、あなたの組み合わせ推定と現在の市場価格との間に差があるかどうかを簡単に確認してください。
差がある場合、おめでとうございます、あなたはちょうど単純化されたアルファ組み合わせを手動で完成させました。
お勧めの読書:Edward Thorpの『A Man for All Markets』。Thorpは、投資領域でケリーの式を先駆的に応用した人物で、この本では、彼がどのように数学を使用してカジノとウォール街の両方でお金を稼いだかが非常にわかりやすい言葉で語られています。
パート6:insiders.botを使用してこのシステムを実装する
ここまで見て、あなたはおそらく考えるでしょう:このシステムの論理は理解したけれども、一人でゼロから構築することはどうやって可能なのか?
良いニュースは、ゼロから始める必要がないということです。
Insiders.bot(@insidersdotbot)を行う中で、この記事で触れられている「Active Management Basic Law」(つまり、IR = IC x √N、全体のパフォーマンスは、1つのシグナルの精度に独立したシグナルの平方根を乗じたものと同等)は、私たちに大きなインスピレーションを与えてくれました。
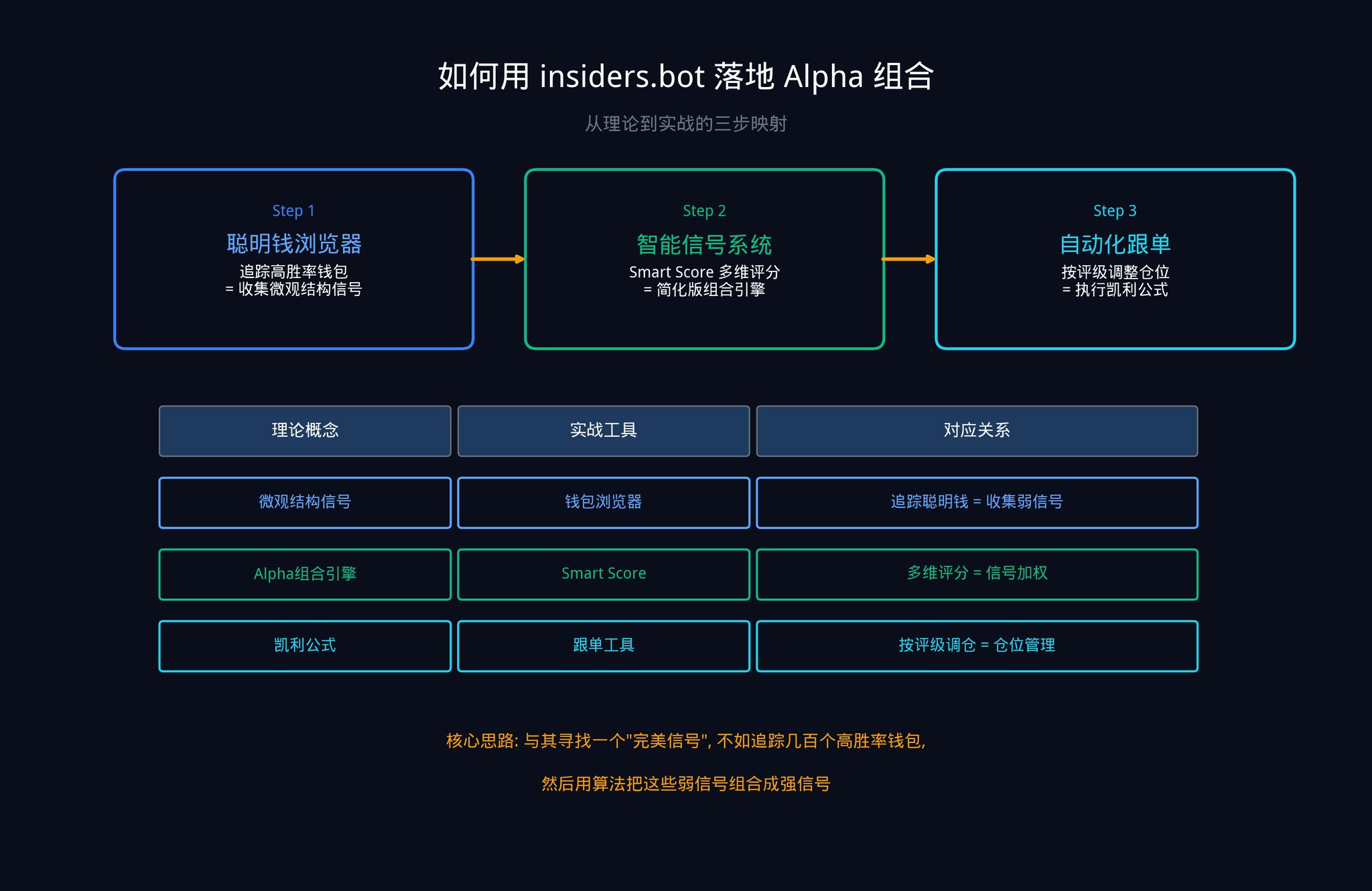
以下は、すぐに実行できる3つのステップです。
ステップ1:スマートマネーブラウザを使用してシグナルの原材料を収集する
Insiders.botのスマートマネーブラウザを開きます。フィルターパネルを使用して、勝率、トータルプロフィット、取引頻度などの次元で、Polymarketで最も優れたパフォーマンスを発揮しているウォレットを見つけます。
これらのウォレットの各変動は、あなたの「ミクロストラクチャシグナル」です(第2セクションで説明した5つのシグナルカテゴリのうちの5番目を覚えていますか?)。個々のウォレットのシグナルは弱いかもしれません(ICが低い)、しかし、数十のウォレットを同時に追跡すると、あなたは記事で説明されている「シグナル組み合わせ」を行っているのです。これがアクティブマネジメントの基本法則の核心です:Nが大きいほど、IRが高くなります。
ステップ2:スマートシグナルシステムを使用してAlpha組合せを実現する
当社のスマートシグナルシステム(SIGNALSタブ)は、本質的にはAlpha組合せエンジンの簡易版です。優良ウォレットが大口取引を行うと、システムはシグナルを生成し、スマートスコアを通じて歴史的な勝率、トータルプロフィット、ベッティングの安定性、カテゴリパフォーマンス、ポジションサイズなど複数の次元を総合評価し、強度評価を行います。
LOW: 基準は満たしていますが、トレーダーアドバンテージは一般的です。低ICシグナルであり、組み合わせるためにはさらに多くの信号が必要です
MEDIUM: 歴史的な記録が良好で、堅実な信念を示しています。中ICシグナルに対応し、適度に配分できます
HIGH: トップパフォーマンスウォレットからの大口取引。高ICシグナルに対応し、組合せエンジンは高いウェイトを与えます
この評価システムは、第3部11ステップエンジンのステップ10(最適なウェイトの設定、つまり各シグナルの独立した貢献と安定性に基づいて資金配分を決定する)と本質的に同じことを行います:多次元の総合評価に基づき、各シグナルに異なるウェイトを割り当てます。
ステップ3:トレードコピー ツールを使用してケリーの公式を実行する
High 評価のシグナルを受信した場合、比率または固定金額でトレードコピーを設定するために当社の自動化ツールを使用できます。
第5部で述べた経験的ケリーの公式(f_empirical = f_kelly x (1 - CV_edge)。すなわち、ベット率は不確実性に基づいて割引する必要があることを覚えておいてください。推定が不確実であるほど、ベットすべき金額は少なくなります。
Low 評価のシグナルに対しては、ポジションを減らします。
High 評価のシグナルに対しては、ポジションを適度に増やすことができます。数学が意思決定を行い、感情がそれを行うのではないようにしましょう。
結論
最初の質問に戻りましょう。
個々のシグナルは弱いです。完璧なシグナルを探すことは、まったく逆方向に向かっています。
主動的運用の基本法則(IR = IC x √N)は、多くの弱い独立したシグナルを組み合わせることが、強力なシグナルを見つけるよりも優れていることを数学的に証明しています。情報比率は、展開された真に独立したシグナルの数の平方根に比例して増加します。
11ステップのアルファ組合せエンジンは、最適な重み付けを計算するための正確な手法を提供します。これらの重みは、各シグナルの独立した寄与を反映し、ノイズをペナルティとして課し、シグナル間の共有分散を排除します。
市場予測に適用すると、このフレームワークは5つ以上の暗黙の確率シグナルを単一の組合せ推定に変換します。この推定は、任意の個々のコンポーネントよりも正確であることが証明されています。
経験的ケリーの公式をポジション管理に組み込むと、ポジションは、実際にどれだけ自信があるかを正確に反映し、自身がどれだけ自信があるかを感じるかを反映します。
複利の最大の利点は、あなたが本当に知っていることに基づいた最も誠実なモデルの上に構築されています。
最後に、1つ考えてほしい質問を残します:
何百ものシグナルを組み合わせた機関取引所でさえ、情報比率が0.05から0.15の間しか達成できない場合、いかなる単一モデルからも高い信頼度で勝者を持続的に選択できると主張するシステムは、一体何を言っているのでしょうか?
発展的な読み物と参考文献
さらなる研究を希望する場合は、以下はいくつかの上級資料です:
初級:
Harvard Stat 110: 確率論へのイントロダクション(無料オンライン教材)。確率論の基礎、最初の 6 章が十分です。
Edward Thorp, すべての市場に生きる男。ケリーの公式の先駆者の自伝で、数学がカジノやウォール街でどのようにお金を稼ぐかを平易な言葉で説明しています。
中級:
Grinold & Kahn、アクティブポートフォリオマネジメント。量的投資分野の「聖書」であり、アクティブマネジメントの基本的な法則を詳細に導出しています。
MIT 18.06 線形代数。Gilbert Strang 教授のクラシックコースで、直交化の理解に最適なリソースです。
上級:
Marcos Lopez de Prado、金融機械学習の進歩。現代の量的手法に関する必読書であり、特にクロスバリデーション、特徴の重要性、および直交化に関する部分について説明しています。
Easley、Lopez de Prado & O'Hara(2012年)、高頻度ワールドにおける流動性と流動性、金融研究のレビュー。 VPIN インジケータの元の論文。
Original Link
BlockBeats の公式コミュニティに参加しよう:
Telegram 公式チャンネル:https://t.me/theblockbeats
Telegram 交流グループ:https://t.me/BlockBeats_App
Twitter 公式アカウント:https://twitter.com/BlockBeatsAsia