
a16z:AIの「健忘症」、持続的学習がそれを「治」せるか?

原文タイトル:なぜ私たちは継続的学習が必要なのか
原著者:Malika Aubakirova、Matt Bornstein,a16z crypto
原文翻訳:TechFlow
クリストファー・ノーランの映画『メメント』の中で、主人公レナード・シェルビーは壊れた現在に生きています。脳の損傷により、逆行性健忘症になり、新しい記憶を形成することができません。数分ごとに、彼の世界はリセットされ、時間が永遠の「今」に固定され、何が起こったか覚えておらず、これからどうするかもわかりません。生き抜くために、彼は身体にタトゥーを入れ、ポラロイド写真を使って自分の代わりに記憶機能を補完しています。
大規模言語モデルも同様の永遠の現在に生きています。トレーニングが終了すると、膨大な知識がパラメータに凍結され、モデルは新しい記憶を形成できず、新しい経験に基づいて自らのパラメータを更新できません。この欠陥を補うために、私たちは多くの足場を組み立てました:チャット履歴が短期メモとして機能し、検索システムが外部ノートブックとして機能し、システムのヒントワードがタトゥーのように機能します。しかし、モデル自体は、これらの新しい情報を実際に内面化したことはありません。
ますます多くの研究者が、これでは不十分だと考えています。上下文学習(ICL)が対処できる問題は、答え(または答えの一部)が既に世界のどこかに存在している場合に適しています。しかし、本当に発見する必要がある問題(新しい数学の証明など)、敵対的なシナリオ(セキュリティ攻撃/防御など)、または言葉で表現できないほどに潜在的な知識が必要な場合には、モデルが展開後に新しい知譡と経験を直接パラメータに書き込む方法が必要だという十分な理由があります。
上下文学習は一時的なものです。真の学習には圧縮が必要です。モデルが継続的に圧縮できる前に、私たちは『メメント』の永遠の現在に閉じ込められているかもしれません。逆に、モデルに自身のメモリ構造を学習させることができれば、カスタムツールに頼らずに、新しいスケーリング次元が開放される可能性があります。
この研究分野は継続的学習と呼ばれています。この概念は新しいものではありません(McCloskey と Cohen の1989年の論文を参照)。しかし、過去2〜3年間におけるモデルの能力の急激な向上により、モデルの「知っていること」と「知ることができること」との間の溝がますます明確になっています。この記事の目的は、この分野のトップ研究者から学んだことを共有し、継続的学習の異なる経路を整理し、このトピックを起業家のエコシステムで進展させるのに役立つことです。
注:この記事の構築は、優れた研究者、博士課程学生、起業家のグループとの深い対話によって支えられています。彼らは、継続的な学習領域での作業や見解を私たちと気前よく共有してくれました。理論的基盤からエンジニアリングの現実まで、彼らの洞察力は、この記事を私たちだけで書いたよりもはるかに堅固にしました。貴重な時間とアイデアを提供していただいた皆様に感謝申し上げます!
まずは文脈について話してみましょう
パラメーターレベルの学習(つまりモデルの重みを更新する学習)を擁護する前に、1つの事実を認める必要があります:文脈学習は確かに有効です。さらに、それは今後も有効であるという非常に強力な主張があります。
Transformerの本質は、シーケンスベースの次のトークン予測器に基づいています。正しいシーケンスを与えると、重みを変更する必要がなくとも驚くほど豊かな振る舞いが得られます。これが、文脈の管理、プロンプトエンジニアリング、指示微調整、少量のサンプルの例などの方法が非常に強力である理由です。知性は静的なパラメーターに包まれており、窓に供給されるコンテンツに応じてドラマチックに変化します。
最近、Cursorは自律プログラミングエージェントのスケーリングに関する深い記事を発表しましたが、モデルの重みは固定されており、システムを実行する実質的な要素は慎重に編成されたコンテキストです。何を入れるか、いつ要約をするか、数時間にわたる自己運用の中で一貫性を維持する方法などがキーです。
OpenClawも良い例です。特別なモデルの権限があるわけではなく(基本的なモデルは誰でも使用できます)、コンテキストとツールを非常に効果的に作業状態に変換しました。何をしているかを追跡し、中間生成物を構造化し、いつプロンプトワードを再挿入するかを決定し、以前の作業についての持続的な記憶を維持します。OpenClawは、エージェントの「外部デザイン」を独立した学問的レベルにまで引き上げました。
プロンプトエンジニアリングが最初に登場したとき、多くの研究者が「プロンプトワードだけに頼ることが真面目なインターフェースになるかどうか」について疑問を抱いていました。それはハックのように見えました。しかし、それはTransformerアーキテクチャのネイティブな製品であり、再トレーニングが不要であり、モデルの進化とともに自動的にアップグレードされます。モデルが強くなると、プロンプトも強くなります。単純でありながらネイティブなインターフェースはしばしば勝利し、それは直接的に基礎となるシステムにカップリングされており、それと敵対していないためです。これまでのところ、LLMの開発の道筋はまさにそうでした。
状態空間モデル:文脈のステロイド版
主流のワークフローが元のLLM呼び出しからエージェントループに移行すると、文脈学習モデルはますます圧力を受けるようになりました。過去には、文脈ウィンドウが完全に埋められた状況は比較的少なかったです。これは、LLMが長い一連の離散的なタスクを達成するよう要求された場合によく発生し、アプリケーション層がチャット履歴をトリミングおよび圧縮する方法を比較的直接的に使用できました。
しかし、エージェントにとっては、1つのタスクでも利用可能なコンテキスト全体のかなりの部分を必要とする可能性があります。エージェントのループの各ステップは、前の反復で渡されたコンテキストに依存しています。そして、通常、20から100ステップ後に「線が切れる」ため、失敗します:コンテキストが満たされ、一貫性が低下し、収束できなくなります。
したがって、主要なAI研究所は現在、超長いコンテキストウィンドウのモデルを開発するために大量のリソース(すなわち、大規模なトレーニングラン)を投入しています。これは自然な進化であり、既存の効果的な手法(コンテキスト学習)に基づいており、産業全体の推論時計算への移行の大きなトレンドと一致しています。最も一般的なアーキテクチャは、固定メモリレイヤーを通常のアテンションヘッドと交互に挿入する方法です。つまり、ステートスペースモデル(SSM)および線形アテンションの変種(以下、SSMと総称されます)。SSMは、長いコンテキストシナリオでより良いスケーリング曲線を提供します。
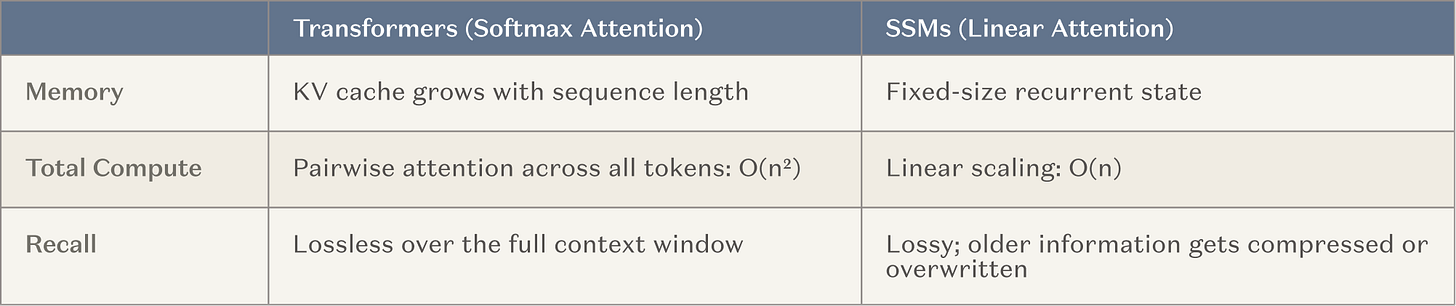
図説:SSMと従来のアテンションメカニズムのスケーリング比較
目標は、エージェントが連続して実行できるステップ数を数桁増やし、約20ステップから約20,000ステップに引き上げることであり、同時に、従来のTransformerが提供する広範なスキルと知識を失わないことです。成功すれば、長時間実行されるエージェントにとって画期的な進歩となります。
このアプローチをほぼリセットする必要のない外部メモリレイヤーを導入することで、この方法はほぼ永続的な学習形式と見なすことさえできます。
したがって、これらの非パラメトリックな方針は現実的であり、強力です。持続的学習の評価は、この点から始める必要があります。問題は、現在のコンテキストシステムが役立っているかどうかではなく、確かに役立っているという点です。問題は、私たちが天井を見てしまったかどうか、新しい方法が私たちをさらに前に進めるかどうかです。
コンテキストが見落としているもの:「書類棚の誤謬」
「AGIと事前トレーニングの事象は、ある意味では過剰適合していました……人間はAGIではありません。はい、人間にはスキルベースがありますが、大量の知識が欠けています。私たちが依存しているのは持続的学習です。
私が超頭脳的な15歳の少年を作り出したら、彼は何も知りません。熱心な学生、学びたがり。プログラマーになるなど言えるでしょう、医師になるなど。展開自体は、ある種の学習、トライ&エラーのプロセスが関わります。これはプロセスであり、完成品をただ投げ出すわけではありません。——Ilya Sutskever」
無限のストレージスペースを想像してください。世界最大のファイリングキャビネットで、すべての事実が完璧にインデックスされ、即座に検索可能です。何でも調べることができますか?
いいえ。それは圧縮を無理やり行ったことがありません。
これが私たちの主張の核心であり、以前 Ilya Sutskever が提唱した視点を引用しています:LLM は本質的には圧縮アルゴリズムです。トレーニング中、彼らはインターネットをパラメータに圧縮します。圧縮は情報損失がありますが、この情報損失こそが彼らを強力にしています。圧縮によって、モデルは構造を見つけ、一般化し、文脈を超えて転移可能な表現を構築します。すべてのトレーニングサンプルを暗記するモデルよりも、基礎となるパターンを抽出するモデルのほうが優れています。情報損失のある圧縮そのものが学習です。
皮肉なことに、LLM にトレーニング中にこのように強力に作用させたメカニズム(元のデータをコンパクトで転移可能な表現に圧縮する)は、デプロイ後にその継続を拒否することを拒絶することが私たちには優先されます。私たちはリリース時に圧縮を停止し、外部メモリでそれを置き換えます。
もちろん、ほとんどのインテリジェント エージェント シェルは、ある種のカスタム方式でコンテキストを圧縮します。しかし、時には、苦い教訓は、モデル自体がこのような圧縮を直接的かつ大規模に学ぶべきであることを示すものではないでしょうか?
Yu Sun は、この議論を説明する例を共有しました:数学。フェルマーの最終定理を見てください。350 年以上も、数学者はそれを証明することができずにいました。それは彼らが正しい文献情報を持っていないためではなく、解法が非常に斬新だからです。既存の数学の知識と最終的な答えとの間には、概念上の差が大きすぎました。
1990 年代に Andrew Wiles がついにそれに挑戦したとき、彼はほぼ孤立して七年間の作業をし、答えに到達するために全く新しい技術を発明しなければなりませんでした。彼の証明は、異なる数学分野、楕円曲線と模形式を成功裏に結びつけるための新しい技法に依存していました。Ken Ribet は以前に、この接続を確立できれば、フェルマーの最終定理が自動的に解決されることを証明していましたが、Wiles の前では、それを構築するための理論ツールを持っている人はいませんでした。Grigori Perelman もポアンカレ予想の証明について同様の議論ができます。
核心問題は: これらの例が LLM が何か欠けていること、新しい先験、真の創造的思考能力を欠いていることを証明しているのか、それともこのストーリーがまさに逆の結論を証明しているのか、つまりすべての人類の知識は単なるトレーニングと再構築可能なデータであり、Wiles と Perelman は LLM がより大規模にも達成できることを示しているだけなのか、ということです?
この問題は経験的なものであり、答えはまだ確定していません。しかし、今日、文脈学習が失敗する多くのカテゴリの問題を知っていますが、パラメータレベルの学習が有効であることも知っています。例えば:

注:文脈学習の失敗、パラメータ学習が優れる可能性のある問題カテゴリ
さらに重要なのは、文脈学習が言葉で表現可能なものにのみ対処できる一方、重みはテキストで伝えられない概念をエンコードできることです。一部のパターンは次元が高すぎたり、非常に内在的であり、文脈の中には収まりきれないほど深い構造化されたものです。たとえば、医療スキャンでの良性擬態と腫瘍の視覚的なテクスチャの区別、または話者固有のリズムを定義するオーディオの微妙な変動など、これらのパターンは正確な語彙に分解しにくいものです。
言語はこれらを近似するだけです。ヒントの長さがどれだけ長くても、これらの要素は伝えられません。このような知識は重みに保存されるだけで、表層のテキストではなく、学習表現の潜在空間に存在します。文脈ウィンドウがどれだけ大きくなろうとも、テキストでは記述できない知識がいくつか存在し、それらはパラメータによってのみ保持されます。
これは、例えば ChatGPT のメモリなど、明示的な「ロボットがあなたを覚えている」機能がユーザーに驚きではなく不快感を与える理由を説明するかもしれません。ユーザーが本当に求めているのは「記憶」ではなく「能力」です。あなたの行動パターンを内面化したモデルは新しいシナリオにも一般化できますが、過去の記録を単に思い出すモデルはそれができません。「前回このメールに返信したときに書いた内容」(逐語的な再現)と、「あなたの思考方法を十分理解し、必要があるかを予測できる」こととの差は、リトリーブと学習の違いです。
継続的学習入門
継続的学習にはさまざまな進むべき道があります。分かれ目は「記憶機能があるかどうか」ではなく、どこで圧縮が起こるかにあります。これらの道は無圧縮(純粋な検索、重み固定)から完全な内部圧縮(重みの段階的学習、モデルがより賢くなる)、またその中間に重要な地帯(モジュール)があります。
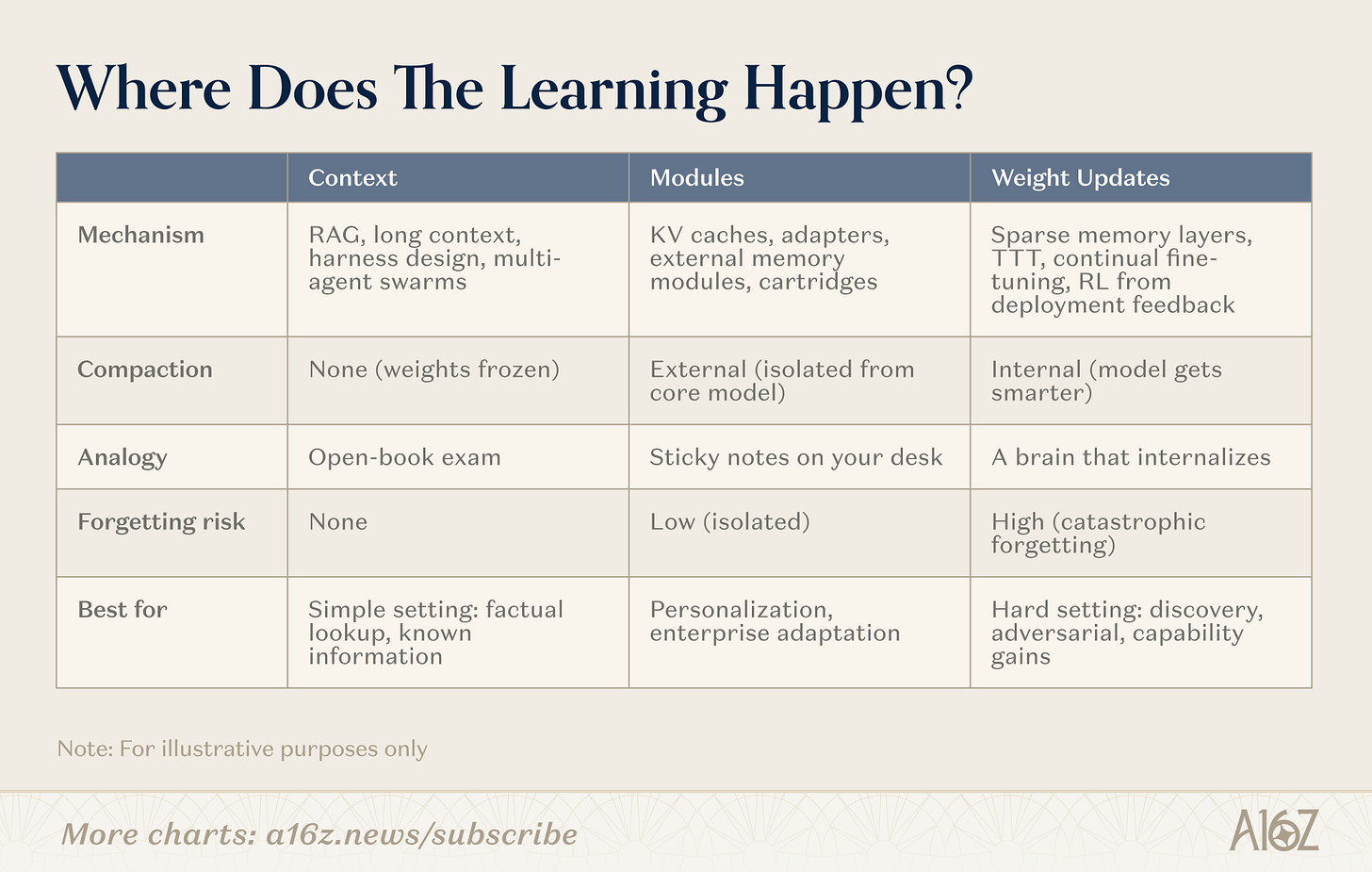
注:継続的学習の三つのパス - コンテキスト、モジュール、重み
コンテキスト
コンテキストの側面では、チームはよりスマートな検索パイプライン、エージェントシェル、およびヒントの配置を構築しています。これは最も成熟したカテゴリであり、インフラストラクチャが検証され、展開経路が明確です。制約は深さにあります:コンテキストの長さ。
注目すべき新しい方向性:マルチエージェントアーキテクチャがコンテキスト自体のスケーリング戦略として機能しています。単一モデルが128K トークンウィンドウ内に制約されている場合、調整されたグループのエージェント集団 - 各々が独自のコンテキストを持ち、問題のスライスに特化し、結果を共有する - は、全体として近似無限のワーキングメモリを実現できます。各エージェントは自らのウィンドウでコンテキスト学習を行い、システムが集約します。Karpathy の最近の autoresearch プロジェクトや、Cursor によるウェブブラウザの構築の例は、初期の事例です。これはパラメトライゼーションの方法ではなく(重み変更なし)、コンテキストシステムが達成できる限界を大幅に引き上げました。
モジュール
モジュール空間では、チームはプラグアンドプレイの知識モジュールを構築します(圧縮された KV キャッシュ、アダプターレイヤー、外部メモリストレージ)、これにより一般的なモデルを再トレーニングせずに専門化できます。適切なモジュールを備えた 8B モデルは、目標タスクで 109B モデルと同等のパフォーマンスを発揮しますが、メモリ使用量はごくわずかです。魅力的な点は、既存の Transformer インフラストラクチャと互換性があることです。
ウェイト
ウェイトの更新において、研究者は本当のパラメーターレベルの学習を追求しています:関連するパラメーターセグメントだけを更新するスパースなメモリレイヤー、フィードバックからモデルを最適化する強化学習サイクル、推論時にコンテキストをウェイトに内包させるテスト時トレーニングなどの方法を取り入れています。これらは最も深いアプローチであり、同時に最もデプロイが難しいものですが、これによりモデルが完全に新しい情報や新しいスキルを内部化できるようになります。
パラメーターの更新メカニズムにはさまざまな種類があります。いくつかの研究方向を挙げると:
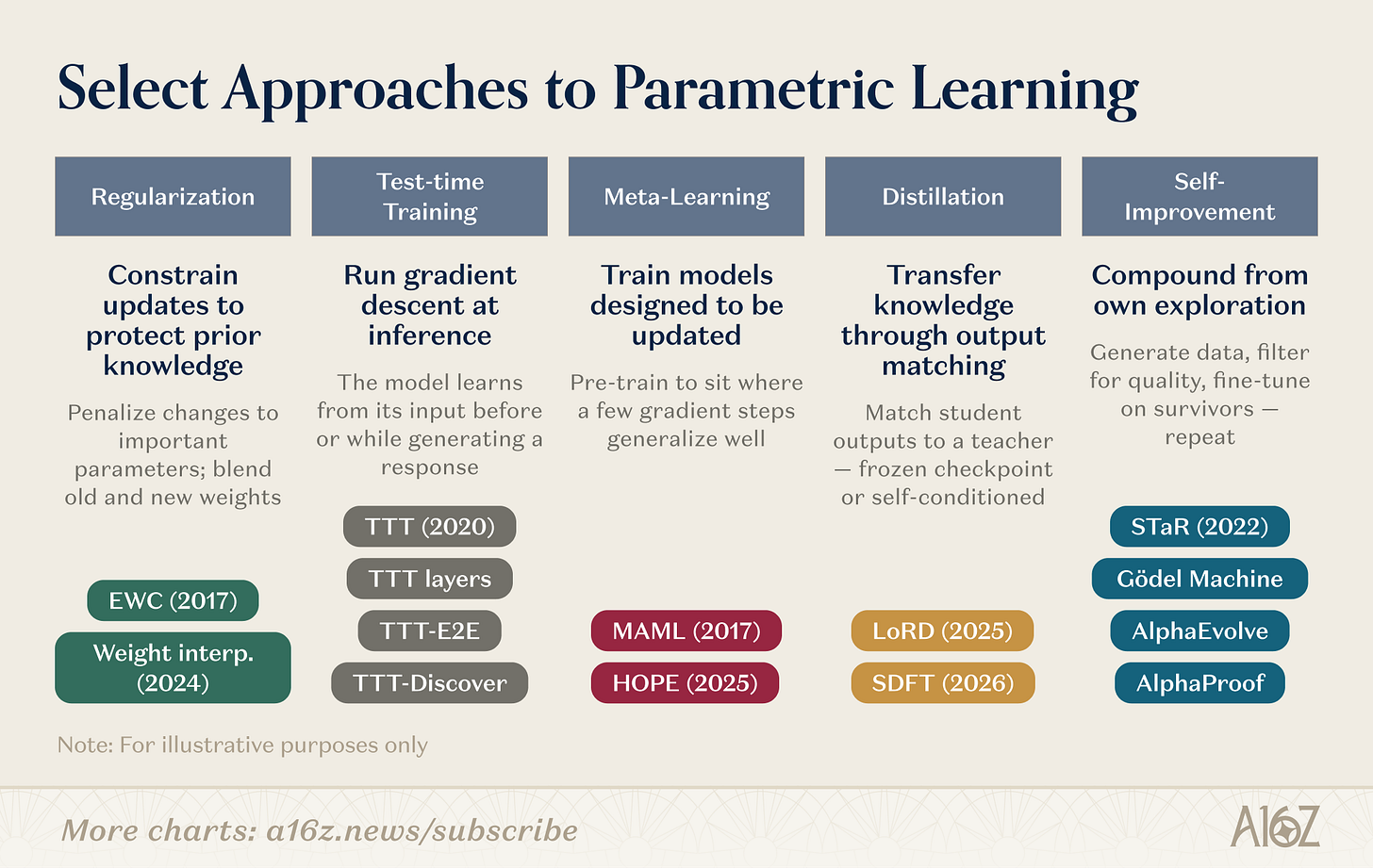
図説:ウェイトレベルの学習の研究方向概要
ウェイトレベルの研究には複数の並行する道があります。正則化およびウェイトスペース法はもっとも長い歴史を持っています:EWC(Kirkpatrick ら、2017)は以前のタスクに対するパラメーターの重要性に基づいてパラメーターの変化にペナルティを科します。ウェイト補間法(Kozal ら、2024)は新旧のウェイト構成をパラメーター空間で混ぜ合わせますが、どちらも大規模な適応には弱い傾向にあります。
テスト時トレーニングは Sun ら(2020)によって提唱され、後にアーキテクチャプリミティブ(TTT レイヤー、TTT-E2E、TTT-Discover)へと発展しました。その着想は全く異なり、テストデータ上で勾配降下を行い、新しい情報を必要とする時点でその情報をウェイトに圧縮します。
メタラーニングはこう問います:モデルが「学び方」を理解することは可能でしょうか?MAML の少数サンプルフレンドリーなパラメーター初期化(Finn ら、2017)から Behrouz らのネステッドラーニング(Nested Learning、2025)まで、後者はモデルを階層的な最適化問題として構造化し、異なる時間尺度で高速適応と遅い更新のモジュールを実行します。これには生物学的なメモリの強化から着想を得ています。
蒸留 は、生徒モデルを凍結された教師のチェックポイントに合わせることで、以前のタスクの知識を保持します。LoRD(Liu et al.、2025)は、モデルを同時に刈り込み、再生バッファを回復することで、蒸留を効率的に行い、持続可能にしました。自己蒸留(SDFT、Shenfeld et al.、2026)は、ソースを反転し、モデル自体の専門家条件下の出力をトレーニングシグナルとして使用し、シーケンスのファインチューニングの災害的な忘却を回避しました。
再帰的自己改善 は同様の考え方で機能します:STaR(Zelikman et al.、2022)は、自己生成された推論チェーンから推論能力を導き出します;AlphaEvolve(DeepMind、2025)は、数十年間改善されていなかったアルゴリズムの最適化を発見しました;Silver and Suttonの「エクスペリエンス時代」(2025)は、エージェントの学習を永遠に続く持続的な経験の流れと定義しました。
これらの研究方向は収束しています。TTT-Discover はテスト時トレーニングと RL ドライブの探索を融合しています。HOPE は速度の異なる学習を単一のアーキテクチャにネストしています。SDFT は蒸留を自己改善の基本的な操作に変えました。列と列の間の境界がぼやけつつあります。次世代の持続的学習システムはおそらく、正規化を安定させ、メタ学習を加速させ、自己改善を複利にするために複数の戦略を組み合わせるでしょう。ますます多くの新興企業が、この技術スタックの異なるレベルに賭けています。
持続的学習の起業家マップ
最も知られているのは、スペクトルの非パラメトリックエンドです。Husk Companies(Letta、mem0、Subconscious)は、コンテキストウィンドウに入れるコンテンツを管理するオーケストレーションレイヤーと足場を構築しています。外部ストレージと RAG インフラストラクチャ(Pinecone、xmemoryなど)は、リカバリバックボーンを提供しています。データの存在そのものは問題ではなく、問題は適切なスライスをいつ提供すべきかです。コンテキストウィンドウが拡大するにつれて、これらの企業の設計空間も拡大し、特にHusk側では、ますます複雑なコンテキスト戦略を管理するために新しい起業家が現れています。
パラメータエンドは、より初期の段階であり、より多様です。ここでは、企業がある種の「展開後の圧縮」バージョンを試しており、モデルが重みの中に新しい情報を内包するようにしています。パスは大まかに、モデルがリリース後にどのように学習すべきかについての異なる賭けに分けられます。
部分的圧縮: 再トレーニングなしで学習。 一部のチームは、プラグアンドプレイの知識モジュール(圧縮された KV キャッシュ、アダプターレイヤー、外部メモリストレージ)を構築し、汎用モデルをコアウェイトを動かさずに専門化することができるようにしました。共通の議論は:意味のある圧縮を実現できるということ(検索だけでなく)、同時に安定性-プラスチシティのバランスを管理可能な範囲内に保ち、学習が分散されるのではなく、隔離されるので、実験コストが再トレーニングよりもはるかに低く抑えられます。
RL とフィードバックループ:信号からの学習。 一部のチームは、デプロイ後の学習で最も豊富な信号が既にデプロイメントループそのものに存在していると賭けています — ユーザーの訂正、タスクの成功または失敗、現実の世界の結果からの報酬信号。中心的な考え方は、モデルが各インタラクションを潜在的なトレーニング信号として扱うべきであり、推論リクエストだけでないということです。これは、人間が仕事で進歩する方法と非常に似ています:仕事をし、フィードバックを受け取り、どの方法が効果的かを内面化する。エンジニアリング上の課題は、希少でノイジーで時には敵対的なフィードバックを安定した重み更新に変換することですが、災害的な忘却を引き起こさないようにすることです。しかし、デプロイメントから学習することができる本当のモデルは、上下文システムが到達できない方法で複利価値を生み出します。
データ中心:正しい信号から学習。 関連があるが独自の賭け方は、学習アルゴリズムではなく、トレーニングデータと周辺システムにボトルネックがあるというものです。これらのチームは、継続的な更新を駆動するために正しいデータを選別、生成、または合成することに焦点を当てています — 前提は、高品質で構造化された学習信号を持つモデルが、はるかに少ない勾配ステップで意味のある改善を達成できるというものです。これはフィードバックループ企業と自然に連携していますが、強調されるのは上流の問題です:モデルが学習することができるのは一つのことであり、何から学び、どの程度学ぶべきかは別のことです。
新しいアーキテクチャ:底層設計からの学習能力。 最も積極的な賭けは、Transformer アーキテクチャそのものがボトルネックであり、持続的な学習には根本的に異なる計算原理が必要であると考えています:連続時間のダイナミクスと組み込みメモリメカニズムを備えたアーキテクチャ。ここでの主張は構造的です:継続的な学習システムが必要ならば、学習メカニズムを基盤とするインフラストラクチャに埋め込む必要があります。

図説:持続的学習スタートアップの領域
すべての主要な研究所も、これらのカテゴリの中で積極的に展開しています。いくつかは、より良いコンテキスト管理と思考フレーム推論を探求しています、いくつかは外部メモリモジュールや睡眠時間計算パイプラインを試験しています、さらにいくつかのステルス企業は新しいアーキテクチャを追求しています。この分野はまだ初期段階であり、どの手法が勝利するかは決まっておらず、ユースケースの幅広さを考慮すると、単一の勝者にすべきではありません。
なぜ素朴な重み更新が失敗するのか
生産環境でモデルパラメータを更新すると、大規模な未解決の失敗モードが引き起こされます。

図説:素朴な重み更新の失敗モード
エンジニアリングの問題は十分に記録されています。災害的な忘却は、新しいデータに対して十分に敏感であることを意味し、学習済みモデルが持っていた表現 - 安定性 - 可塑性のジレンマを破壊することになります。時間の逆結合は、不変のルールと可変の状態が同じ重みのセットに圧縮され、1つを更新するともう1つが壊れてしまうことを指します。論理の統合の失敗は、事実の更新がその推論に伝播しないためです。変更はトークンシーケンスのレベルでのみ制限され、意味論的概念のレベルではありません。忘却(unlearning)はまだ不可能です。差分可能な減算操作は存在せず、したがって誤ったまたは有害な知識には正確な手術的摘出法がありません。
二次問題も少なくとも注目されています。現在のトレーニングとデプロイメントの分離は単なるエンジニアリング上の利便性ではなく、セキュリティ、監査可能性、およびガバナンスの境界でもあります。この境界を開くと、複数の問題が同時に発生します。セキュリティアライメントは予測不可能に劣化する可能性があります。データ毒入攻撃面が作成され、遅延型のヒントが注入されますが、それは重みに存在します。監査可能性が崩壊し、継続的に更新されるモデルは移動する標的であり、バージョン管理、回帰テスト、または一括認証を行うことができません。ユーザーインタラクションがパラメータに圧縮されると、プライバシーのリスクが高まり、機密情報が表現に焼き込まれ、情報を検索コンテキストから取り出すよりもフィルタリングが難しくなります。
これらは根本的に不可能なものではなく、未解決の問題です。これらを解決することは、核心アーキテクチャの課題を解決することと同様に、持続的な研究アジェンダの一部です。
「断片的記憶」から真の記憶へ
Leonardの『Memento』における悲劇は、彼が稼働できないことにあるのではなく、彼はどのシーンでも十分な知能を持っており、出色とさえ言えます。彼の悲劇は、彼が利益を得ることができないことにあります。彼の経験はすべて外部に留まっており、ポラロイド写真、刺青、他人の手書きのメモなどです。彼は取り出すことができますが、新しい知識を圧縮することはできません。
Leonardがこの自己構築の迷路を歩いているとき、現実と信念の間の境界がぼやけ始めます。彼の病気は彼の記憶を奪うだけでなく、彼を挑発し続けることで、意味を常に再構築させました。彼は同時に自分自身の物語の探偵であり、信頼できない語り手になりました。
今日のAIも同様の制約の下で運用されています。私たちは非常に強力な検索システムを構築しました:より長いコンテキストウィンドウ、よりスマートな外装、調和のとれた複数のエージェントグループであり、うまく機能しています。しかし、検索は学習とは異なります。すべての事実を検索できるシステムは、構造を探しに行くことが強制されていません。それは一般化されることも強制されていません。トレーニングを非常に強力にする有損圧縮を可能にする - 元のデータを移植可能な表現に変換するメカニズム - は、展開時にオフにされるものです。
前進するパスはおそらく単一の突破ではなく、階層化されたシステムである可能性が非常に高いです。文脈学習は依然として第一適応ラインであり続けます:それはネイティブであり、検証済みであり、改良が続いているものです。モジュールメカニズムは個別化およびドメイン専門化の中間地帯を処理できます。
しかし、本当に難しい問題に対しては——発見、適応への対処、言葉で表現できない暗黙の知識——モデルにトレーニング後も経験をパラメータに圧縮し続けさせる必要があるかもしれません。これは疎な構造、メタラーニング目標、および自己改善サイクルの前進を意味します。また、「モデル」の意味を再定義する必要があるかもしれません:固定された重みのセットではなく、進化するシステムであり、そのメモリ、更新アルゴリズム、および自己経験から抽象化された能力を含むものです。
アーカイブはますます大きくなっています。しかし、どれほど大きなアーカイブでも、それはアーカイブにすぎません。突破口は、展開後のモデルにトレーニングを続けさせることでモデルを強力にすることです:圧縮、抽象化、学習。私たちは、記憶のないモデルから少しの経験を持つモデルへの転換点に立っています。さもないと、私たちは自分自身の「記憶の破片」に閉じ込められてしまいます。
原文リンク
BlockBeats の公式コミュニティに参加しよう:
Telegram 公式チャンネル:https://t.me/theblockbeats
Telegram 交流グループ:https://t.me/BlockBeats_App
Twitter 公式アカウント:https://twitter.com/BlockBeatsAsia







